The New Product Sense: Knowing When AI Should Stop
The New Product Sense: Knowing When AI Should Stop
Why the Most Important AI Product Decision Is Where Autonomy Ends
Executive Summary
For decades, product managers were rewarded for removing friction. The best products reduced clicks, eliminated approvals, simplified workflows, and accelerated the path from intent to outcome. That philosophy emerged during an era when software was fundamentally deterministic: given the same input, the system produced the exact same output every time.
AI changes the optimization problem. Large Language Models, agentic loops, and autonomous workflows operate probabilistically. They do not simply succeed or fail. They drift, degrade, accumulate uncertainty, and occasionally remain highly confident while being completely wrong.
As a result, the defining challenge of modern product management is no longer deciding what the AI should do. It is deciding when the AI should stop.
AI product leaders should not be defined by how much automation they create. Instead, they should be defined by how intelligently they design the boundaries around that automation. This requires transitioning from a mindset of absolute friction removal to dynamically engineering the Friction Vector.
The Automation Trap
Most AI roadmaps begin with a deceptively simple question: What can we automate? Teams identify workflows, connect models to system tools, build multi-agent orchestrations, and gradually increase autonomy. The underlying assumption is straightforward:
$$\text{More Autonomy} = \text{More Value}$$
In practice, the relationship is rarely linear. As autonomy increases, systems accumulate hidden non-linear liabilities:
$$\text{Uncertainty} \;\longrightarrow\; \text{State Drift} \;\longrightarrow\; \text{Context Degradation} \;\longrightarrow\; \text{Debugging Complexity} \;\longrightarrow\; \text{Oversight Costs}$$
Product Value
▲
│ /\
│ / \
│ / \
│ / \
│ Simple / \ Complex Multi-Agent
│ RAG & / \ Chains (State Decay,
│ Regex / \ Chaos Loops, High TTC)
└────────/──────────────\────────────────►
Simplicity ComplexityBeyond a certain point, additional autonomy creates more operational burden and risk than customer value. The question therefore shifts. Instead of asking: How much can we automate? product leaders must ask: Where should automation intentionally end?
Why Must Product Leaders Adapt?
Imagine an AI-powered insurance claims assistant. A customer uploads a note: "My car was damaged in a parking lot."
The system extracts the basic metadata, identifies policy coverage, estimates eligibility, and recommends a reimbursement amount. At the beginning of this workflow, the system is highly confident. But as additional information is processed, uncertainty begins to accumulate: missing incident details, ambiguous policy language, and conflicting historical claim patterns.
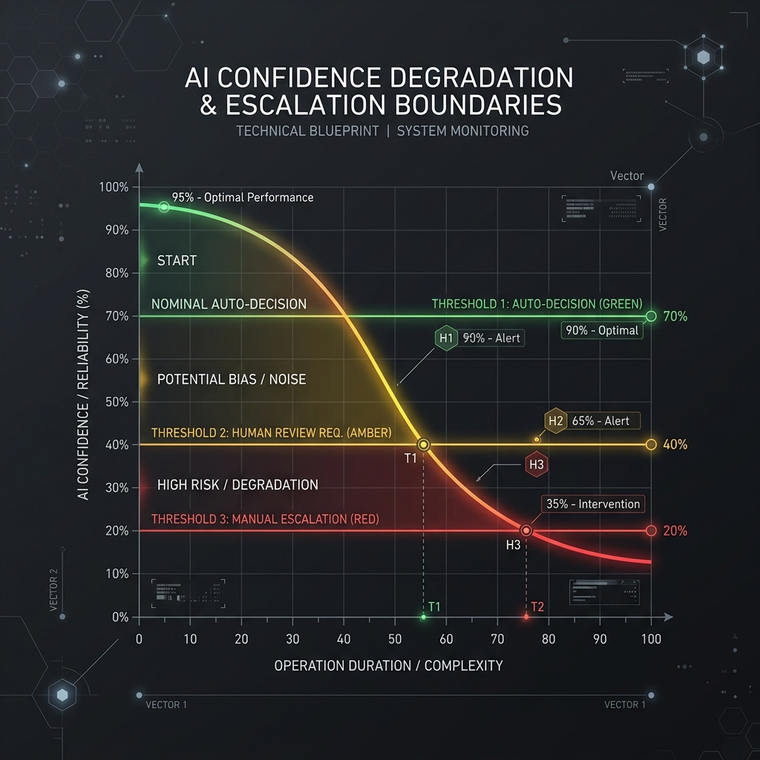
This confidence degradation is gradual, not catastrophic. By the time the final recommendation is generated, the system may still produce a structurally coherent answer while operating far outside the confidence envelope that originally justified autonomous execution.
The model didn't fail because it lacked intelligence. The product failed because nobody designed the precise point where confidence degradation should trigger an alternative workflow. The product problem wasn't reasoning; it was escalation.
AI product sense involves understanding when an autonomous system should stop, pause, ask for confirmation, switch to deterministic logic, or hand over to an expert.
Why AI Fails Differently
Traditional software typically fails through explicit, binary exceptions:
$$\text{Success} \longrightarrow \text{Success} \longrightarrow \text{Success} \longrightarrow \text{Failure (Error Code)}$$
AI systems fail through a gradual erosion of confidence:
$$\text{95% Confidence} \longrightarrow \text{89%} \longrightarrow \text{82%} \longrightarrow \text{74%} \longrightarrow \text{Confidently Wrong}$$
The degradation is incremental. The challenge is not simply detecting a hard crash; it is recognizing when system autonomy is no longer justified.
The Missing Product Capability
Most AI discussions focus extensively on model quality, prompt tuning, retrieval strategies, and benchmark scores. Yet many real-world enterprise failures occur because the system lacked a mechanism for deciding when to stop.
Consider the insurance claims assistant again. Each step of claim processing introduces a fraction of uncertainty. By the final recommendation, the system may still produce a structurally coherent answer while operating far outside the confidence range that originally justified autonomous execution.
The model did not necessarily hallucinate, and the backend did not crash. The product failed because nobody designed the boundary between autonomy and oversight.
Section 1: The Anatomy of Context Decay & Control Planes
Deconstructing how multi-agent systems lose structural integrity and why binary success/fail triggers are insufficient.
1.1 Understanding Context Decay & The Drift
As workflows become multi-step and multi-agent, context decays. Each reasoning layer introduces opportunities for information loss, interpretation drift, retrieval mismatch, and planning divergence. This creates the Multi-Agent Illusion—the appearance of coherent orchestration despite growing semantic misalignment underneath.
Rather than waiting for an outright system collapse, PMs must track telemetry that predicts degradation early:
- Semantic Divergence: The vector distance between the original user intent and the current sub-agent task state. When this distance crosses an invariant threshold, the system is no longer solving the user's problem; it is solving its own mutated interpretation of it.
- Confidence Interval Compression: The shrinking separation margin between competing classifications or predictions.
- Recursive Loops: Repeated token sequences, task reallocations, tool-calling, or recursive planning structures indicating the agent is trapped in a semantic dead end.
- State Fragmentation: Conflicting memory, vector retrieval chunks, and tool execution states across multi-agent hand-offs.
1.2 The Three-Zone Operating Model
Traditional software relies on a simple catch-and-recover paradigm. This assumes failures are discrete, identifiable events. Because AI systems degrade continuously, product managers must enforce a Three-Zone State Machine:
- Green Zone (Autonomous): High confidence, low risk. Fully autonomous, frictionless execution.
- Amber Zone (Active Attenuation): Confidence decay detected. The product dynamically adjusts the friction vector to damp down probabilistic noise before it breaches the perimeter. Additional validation is introduced.
- Red Zone (Deterministic Hold): Autonomy is suspended. Immediate execution of a safety protocol: the system freezes the state, voids temporary tokens, and shifts to a hard-coded security posture for expert review.
The Amber zone is where product design actually happens.
Section 2: The PM Framework — The Asymmetric Escalation Matrix
A tactical framework for mapping AI anomalies against operational, financial, and legal risk.
HIGH │ Zone 3: Deterministic Hold │ Zone 4: Human Intervention
│ (Auto-isolate, hard brake) │ (Contextual Hand-off)
Liability/Risk ├───────────────────────────────┼───────────────────────────────
(Financial, Legal) │ Zone 1: Silent Recovery │ Zone 2: Just-in-Time Friction
│ (Deterministic fallback) │ (UI Affirmation)
LOW │ │
└───────────────────────────────┴───────────────────────────────
FAST SLOW
Required Response VelocityThe matrix forces product teams to answer two operational questions simultaneously: How dangerous is the failure, and how quickly must the system respond?
2.1 The Four Quadrants
- Zone 1: Silent Recovery (Low Risk + Fast Velocity): The user never sees the intervention. Examples include seamless fallbacks from an LLM entity extraction failure to a structural regular expression or deterministic lookup table. The objective is invisible resilience.
- Zone 2: Just-in-Time Friction (Low Risk + Slow Velocity): The system requests lightweight validation before proceeding. Examples include requiring an approval click for an AI-generated expense line item or content draft. The objective is micro-verification.
- Zone 3: Deterministic Hold (High Risk + Fast Velocity): The system immediately enters an automated, protected state. Examples include fraud detection lockouts or trading circuit breakers triggered by unusual agent API behavior. The objective is immediate damage containment.
- Zone 4: Human Intervention (High Risk + Slow Velocity): The system packages the decayed context and escalates it to an expert human operator with a defined time-to-live (TTL) parameter. The objective is legally defensible, accountable oversight.
Section 3: Designing & Engineering the Friction Vector
How to design intervention experiences that maximize safety while minimizing user burden.
3.1 The Product Principle
The goal is not to eliminate friction, but to allocate it intelligently. Too little friction creates uncontrolled, high-risk autonomy. Too much friction creates an unusable, slow product. The Friction Vector is the design framework for allocating friction exclusively where it generates more enterprise value than operational cost.
The challenge lies in engineering it as a vector—a force with both a specific magnitude (how much friction) and a direction (where it points the user or system).
[ THE FRICTION VECTOR ]
│
┌──────────────────────────┴──────────────────────────┐
▼ ▼
[ MAGNITUDE ] [ DIRECTION ]
• Micro-frictions (Confirmations) • Human Interventions (HITL)
• High-friction Gates (Appraisal) • Deterministic Circuit-Breakers
• System holds (Token freezes) • Silent Recovery Rerouting3.2 The Glass Box Design Pattern
When an escalation triggers, reviewers must understand what happened, why it happened, and what changed—without digging through raw prompt logs.
+--------------------------------------------------------------------------+
| Escalation Warning: Confidence Drop (71%) |
+--------------------------------------------------------------------------+
| [Causal Trace]: |
| User Intent (Process Invoice) -> Agent Step 3 (Extract Line Items) |
| |
| [Delta Highlight]: |
| Expected Format: USD Currency (Matches contract terms) |
| Extracted Value: "10,000 EUR" (Found in raw invoice line item 4) |
+--------------------------------------------------------------------------+
| [Action Required]: Approve conversion or route to manual billing. |
+--------------------------------------------------------------------------+- The Causal Trace: Visualizing the execution path. A human reviewer should be able to grasp the core reason for an AI escalation within five seconds.
- The Delta Highlight: Show only the explicit difference between the last trusted state and the current questionable state. Humans review changes drastically faster than they review history.
3.3 Calculating the Cognitive Re-entry Tax
Every escalation imposes an operational tax. The product metric that matters here is Time-to-Context (TTC): the total time required for a human reviewer to gain enough situational awareness to make a safe decision. Reducing TTC often creates far greater enterprise value than chasing a minor 2% improvement in model accuracy.
3.4 Productizing the Hand-Off
Great hand-offs are engineered features, not operational afterthoughts.
- Synthesis Filters: Generate concise summaries of the uncertainty and the specific decision required, rather than replaying a raw, multi-paragraph reasoning chain.
- Asynchronous Staging: Batch escalations by semantic similarity or failure pattern rather than standard chronological order. This keeps the human reviewer in a consistent mental context.
Section 4: The Economics of Escalation
The hidden optimization problem behind every AI workflow.
Treating automation as the ultimate goal is a structural mistake. Automation is merely a variable; economic efficiency is the objective. Every intervention introduces distinct costs that must be balanced against the cost of failure.
- Oversight Costs: Human review hours, queue management, and operational staffing.
- User Costs: Frustration, waiting, reduced trust, and product abandonment.
- Autonomous Failure Costs: Direct financial loss, compliance violations, and reputational damage.
Total Cost
▲
│ \ /
│ \ Autonomous Failure / Oversight & User Costs
│ \ Costs / (Review labor, queue delays)
│ \ /
│ \ /
│ \ /
│ \ /
│ \____ ____/
│ \__ __/
│ \___/ ◄──── Optimal Boundary (Lowest Combined Cost)
└────────────────────────────────────────────────────────────────────────►
0% (Pure Manual) 100% (Pure Autonomy)
Level of AutonomyThe ideal escalation point is rarely maximum automation or maximum control. It is the point where the combined system cost is minimized.
Recoverability Is the Product
Traditional SaaS optimized entirely for throughput: $\text{Success} = \text{Throughput}$. AI systems operate on Confidence-Adjusted Throughput:
$$\text{Success} = \text{Throughput} \times \text{Confidence} \times \text{Recoverability}$$
The capability to safely fail and recover is part of the core value proposition.
Section 5: Metrics of Proof
The core performance indicators that validate an escalation architecture.
| Metric | Definition | Target |
|---|---|---|
| Intervention ROI | Value of loss prevented per review dollar spent. | Maximize ($>1.0$) |
| Time-to-Context (TTC) | Speed of human situational awareness during an escalation. | Minimize ($<8\text{s}$) |
| Friction Precision | Percentage of escalations that genuinely required an override. | Optimize ($>85\%$) |
| Cascade Leakage | Failures that bypassed escalation layers entirely. | Hard Zero |
| Recovery Efficiency | Percentage of escalations resolved without a cold workflow restart. | Maximize |
The goal is not to minimize the number of escalations. The goal is to maximize the quality and precision of escalations.
Section 6: The Playbook — Implementing Invariant Perimeters
The operational checklist for product teams building AI control planes.
- Map the Perimeters: Define hard, quantitative boundaries for token budgets, execution depth, tool invocation counts, and maximum acceptable semantic variance.
- Standardize the State Payload: Every agent action must emit an invariant, structured payload containing input metadata, executing prompts, confidence scores, and a causal parent ID. This provides a clear execution lineage for audits.
- Instrument the Intercept: Implement middleware layers that validate output arrays against deterministic constraints before rendering data to users or executing downstream webhooks.
- Design Escalation Before Autonomy: Most teams build the AI workflow first and worry about safety loops later. The reverse is required. Before turning on autonomous execution, define the escalation rules, intervention paths, and accountability boundaries.
Autonomy should emerge inside predefined guardrails, never outside them.
The Audit Note: Invariant perimeters must be validated at runtime via cryptographic signature verification and schema validation of all state payloads prior to triggering any downstream actions or API webhooks.
Conclusion
Traditional PMs asked: Can this workflow be automated? AI PMs must ask: Under what conditions should this workflow stop being automated? This question sits at the intersection of user trust, risk management, economics, operational scalability, and regulatory compliance. Answering it requires systems judgment, not model expertise.
The defining skill of AI product management is increasingly not deciding what the AI should do. It is deciding when the AI should stop.
Trust, accountability, economics, and user experience ultimately converge at that exact boundary: knowing when the system must hand control to something else—whether that is another model, a deterministic rule, or a human being.
Download the Architecture of Proof Checklist
Ready to implement? Get the definitive checklist for building verifiable AI systems.