Proof-Driven Requirements: Why AI Product Execution Cannot Stop at the PRD

The traditional Product Requirement Document (PRD) was designed for a world where execution is mostly deterministic.
You define the inputs. You specify the expected behavior. Engineering builds to specification. QA validates outcomes. If the test suite passes, the feature ships.
That model still works.
But AI systems introduce a different operational reality: behavior cannot be fully specified upfront.
A language model can pass the same scenario repeatedly and then fail when a production user introduces ambiguity, unusual formatting, conflicting instructions, or simply a data distribution your team never anticipated.
The problem is not that AI systems are unreliable. The problem is that product quality can no longer be proven through static requirements alone.
To build reliable AI products at scale, teams should not replace PRDs. They should extend them.
- PRDs define intent.
- Proof-Driven Requirements (PDRs) define evidence.
PDR introduces a second execution layer: a continuous evaluation and telemetry system that turns product quality into something measurable, repeatable, and operational.

The Tension: Delivery Velocity vs. Operating Reliability
Tuning prompts to satisfy individual user complaints without a PDR loop leads to "Prompt Whack-a-Mole"—where fixing one edge case silently degrades another. Reconciling these loops requires treating evaluation as the primary execution layer.
This creates a split between two development paradigms, each optimizing for a different loop:
The PRD-driven Loop (Optimize for Delivery Velocity)
- Deliver Features: Ship new AI capabilities, agents, and prompts quickly.
- Binary QA: Validate using standard "happy path" tests.
- Static Specifications: Requirements are frozen at the design stage.
- High Risk of Silent Failure: The model works in a demo but breaks under real-world ambiguity.
The PDR-driven Loop (Optimize for Operating Reliability)
- Enforce Guardrails: Maintain strict boundaries around cost, safety, and correctness.
- Continuous Evals: Run regression tests against production and synthetic edge cases.
- Dynamic Requirements: Update evaluations and assertions as new failure modes emerge.
- Auditability & Traceability: Collect replayable logs of all transactions for regulatory safety.
For AI products to scale, these loops must be unified. We cannot choose shipping speed at the expense of control, nor can we lock down the AI so heavily that it becomes a rigid, useless heuristic.
From Specifications to Assertions
Subjective requirements fail at scale. Reliable AI products require translating product intent into deterministic, programmatically verifiable assertions.
Traditional requirements describe desired behavior:
“The agent should summarize customer transcripts accurately.”
That sounds reasonable. But it is difficult to evaluate at scale.
Proof-Driven Requirements translate subjective expectations into measurable, programmatic assertions.
- Structural Assertion: Response must strictly conform to JSON Schema $S$.
- Grounding Assertion: Every extracted factual claim must cryptographically or textually trace back to source evidence.
- Safety Assertion: Output risk/toxicity scores must remain below defined thresholds.
- Performance Assertion: Median latency ($p_{50}$) must remain within specified service objectives.
The objective is not perfect outputs. The objective is defining conditions that can be continuously verified.
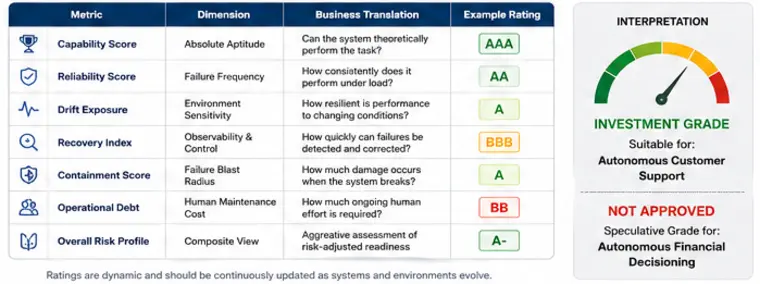
An assertion is not an engineering artifact. It is the PM's primary instrument of accountability. If you cannot define what the system must not do, you cannot govern what it will do.
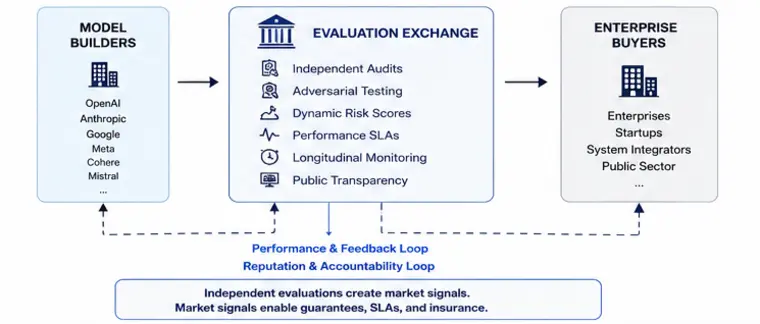
The PDR Lifecycle
Launch is the beginning of requirement discovery, not the end. The PDR lifecycle establishes a continuous feedback loop from production telemetry back to evaluations.
Execution becomes a closed-loop learning system.
flowchart TD
A[Define Assertions] --> B[Build Reliability Layer]
B --> C[Run Evaluation Harness]
C --> D[Deploy]
D --> E[Observe Telemetry]
E --> F[Capture Failures]
F --> G[Update Evaluations]
G --> A
style A fill:#FBF7F0,stroke:#1B1917,stroke-width:2px
style B fill:#FBF7F0,stroke:#1B1917,stroke-width:2px
style C fill:#FBF7F0,stroke:#1B1917,stroke-width:2px
style D fill:#FBF7F0,stroke:#1B1917,stroke-width:2px
style E fill:#FBF7F0,stroke:#1B1917,stroke-width:2px
style F fill:#FBF7F0,stroke:#1B1917,stroke-width:2px
style G fill:#FBF7F0,stroke:#1B1917,stroke-width:2px
Deployment is not completion. Deployment begins evidence collection.
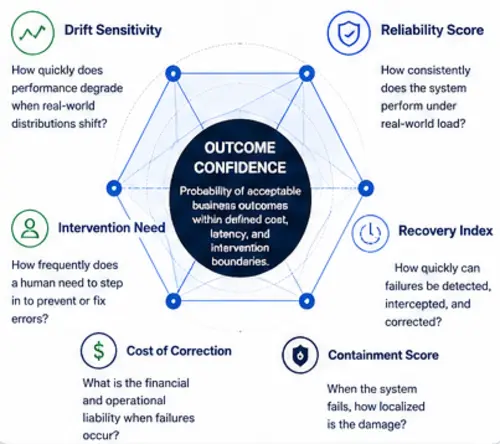
Build the Reliability Layer Around the Model
A reliable AI system is a probabilistic core bounded by deterministic infrastructure. The reliability layer shields both the model from toxic inputs and the user from raw model failures.
Reliable AI systems are rarely just a model. They are deterministic infrastructure wrapped around probabilistic components. The reliability layer exists to contain and constrain uncertainty.
The AI System Architecture
The blueprint below illustrates how runtime transactions are intercepted at both ends, preventing raw user input from hitting the model directly, and shielding the user from raw, unvalidated model behavior.
flowchart TD
A[USER INPUT] --> B[INPUT CONTROLS] --> C[PROMPT / CONTEXT] --> D[LLM CORE]
D --> E[DYNAMIC RETRIES] --> F[OUTPUT CONTROLS] --> G[USER VIEW]
style A fill:#FBF7F0,stroke:#1B1917,stroke-width:2px
style B fill:#FBF7F0,stroke:#1B1917,stroke-width:2px
style C fill:#FBF7F0,stroke:#1B1917,stroke-width:2px
style D fill:#FBF7F0,stroke:#1B1917,stroke-width:2px
style E fill:#FBF7F0,stroke:#1B1917,stroke-width:2px
style F fill:#FBF7F0,stroke:#1B1917,stroke-width:2px
style G fill:#FBF7F0,stroke:#1B1917,stroke-width:2px
Input Controls
Prevent invalid or malicious requests before inference:
- Input normalization & sanitization: Standardizing formats and wiping malicious syntax.
- Intent classification / Routing: Directing the request to specialized local routines rather than an open-ended prompt.
- Token & Cost controls: Applying hard caps to payload sizes before spending compute.
- Context validation: Ensuring Retrieval-Augmented Generation (RAG) inputs are clean, relevant, and secure.
Output Controls
Prevent failures from reaching users:
- Schema validation: Catching malformed JSON at the runtime layer.
- Grounding verification: Running rapid automated sanity checks to flag immediate hallucinations.
- Retry policies: Automatically passing a failed response back to the core for self-correction before throwing an error.
- Deterministic fallbacks & Human escalation paths: Gracefully downgrading to a safe, non-AI circuit breaker if assertions fail.
Evaluation Becomes the Execution Layer
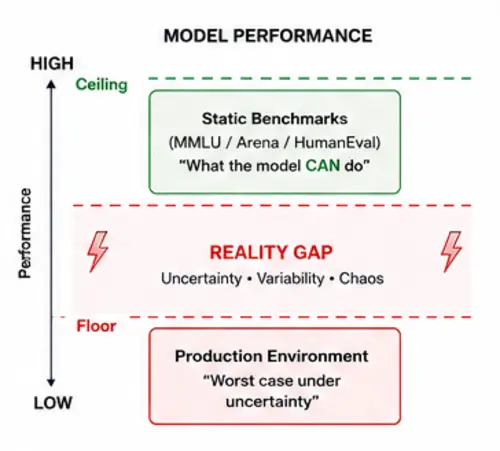
Synthetic test coverage and production observability are not alternatives; they are the twin pillars of a mature evaluation harness.
Traditional testing asks: Does the feature work? AI evaluation asks: Under what conditions does the system remain acceptable?
That requires an evaluation harness. But synthetic testing alone is insufficient. A mature evaluation stack compounds evidence across multiple layers:
flowchart TD
A[Synthetic Edge Cases] --> B[Historical Production Cases]
B --> C[Shadow Traffic]
C --> D[Production Telemetry]
style A fill:#FBF7F0,stroke:#1B1917,stroke-width:2px
style B fill:#FBF7F0,stroke:#1B1917,stroke-width:2px
style C fill:#FBF7F0,stroke:#1B1917,stroke-width:2px
style D fill:#FBF7F0,stroke:#1B1917,stroke-width:2px
- Synthetic evaluations provide coverage.
- Production telemetry reveals reality.
Both are necessary. Shipping criteria evolve from "The code compiles" to "Behavior remains inside acceptable operating boundaries."
Managing the Jagged Frontier
Without systematic regression tracking, tuning AI parameters becomes an endless game of prompt whack-a-mole. PDR turns every production failure into a permanent system constraint.
One of the hardest realities of AI execution is that improvements are rarely isolated. Fix one edge case, another degrades. Tune retrieval, formatting breaks. Switch models, costs shift.
Teams without evaluation discipline often enter an endless cycle engineers recognize immediately: Prompt Whack-a-Mole.
A system prompt changes to satisfy User A. Unexpectedly, User B’s workflow regresses. A retrieval adjustment improves relevance, but latency spikes elsewhere.
PDR introduces a different operating model:
- Detect the anomaly via production alerts.
- Capture the exact runtime payload conditions.
- Convert the failure into a permanent regression test case in your evaluation suite.
- Improve the system parameters.
- Verify that previous system performance remains completely stable across the whole suite.
Every production incident becomes institutional knowledge. Over time, the evaluation harness becomes the living specification.
At agentic scale, this discipline becomes non-negotiable. A single regression that escapes containment does not affect one user flow — it propagates across tool ecosystems, downstream agents, and third-party integrations simultaneously. Without a PDR loop anchoring each agent's behavioral boundaries, a distributed system has no shared definition of acceptable. It has only compounding drift.
The Rule of AI Telemetry
Requirements are not fully discovered before launch. They emerge through runtime evidence. Execution becomes a production learning loop:
$$\text{Telemetry} \longrightarrow \text{Discovery} \longrightarrow \text{Failure Extraction} \longrightarrow \text{Eval Library} \longrightarrow \text{System Improvement} \longrightarrow \text{Redeployment}$$
Your strongest product requirements are often discovered—not written.
Operational KPIs for the AI PM
AI execution changes what product teams optimize. The question is no longer: "How many features shipped?" The question becomes: "How reliably does the system produce acceptable outcomes?"
| Metric | What It Measures | Example Healthy Direction |
|---|---|---|
| Assertion Pass Rate | Reliability across evaluation suite | Improving toward high stability |
| Regression Escape Rate | Failures missed by pre-deployment testing | Near zero for critical paths |
| Silent Failure Rate | User-visible semantic/hallucination failures | Declining over time |
| Fallback Frequency | Dependence on deterministic recovery circuits | Balanced against UX and economics |
| Cost per Successful Outcome | Economic efficiency of autonomous runs | Improving unit economics |
| Time-to-Proof | Speed from issue discovery to validated improvement | Shortening feedback loops |
The exact numbers will vary by domain. The operating model does not. These metrics transform AI delivery from intuition into evidence.
PRDs still matter. But in AI systems, requirements alone are not enough. Product execution becomes the practice of continuously generating proof that the system remains trustworthy as reality changes.
One-Line Synthesis
The traditional PRD only defines intent; in the age of probabilistic AI, the product manager's core delivery is the continuous proof of system reliability.
Download the Architecture of Proof Checklist
Ready to implement? Get the definitive checklist for building verifiable AI systems.