Synthetic Data as AI Infrastructure: Solving the Enterprise Data Access Bottleneck
Enterprise AI projects rarely fail because organizations lack models. They fail because teams cannot safely access the data needed to build, test, evaluate, and scale AI systems.
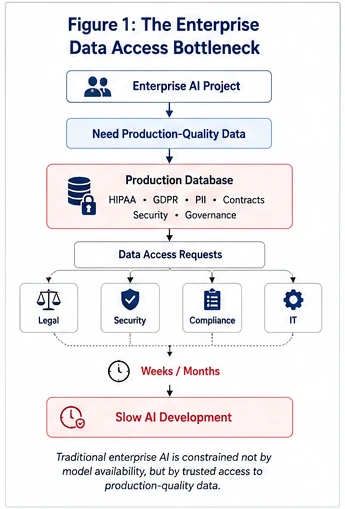
Organizations investing in AI across healthcare, commercial lending, insurance, financial services, and e-commerce frequently discover that their greatest operational constraint isn't algorithmic complexity. It's obtaining realistic data that engineers and product managers can safely use for repeatable experimentation.
Production data is heavily protected by stringent privacy regulations, contractual obligations, internal governance policies, and strict security controls. While these protections are essential, they also create a friction point that slows AI development to a crawl. Engineering teams wait weeks or months for data approvals. Product teams struggle to evaluate new AI workflows. Security teams worry about exposing regulated information. Legal teams face increasing governance responsibilities around how AI systems are validated.
The challenge of enterprise AI is not a cold start for data provisioning; it is a structural data access bottleneck that can only be solved by moving from data protection via restriction to data utility via synthetic infrastructure.
Why This Matters Now: The Agentic Shift
As AI transitions from simple, text-based chatbots to autonomous, multi-step agents, the complexity of testing these systems scales exponentially. Unlike traditional software, AI systems cannot be fully validated with handwritten test cases or simple mock objects. Agents make non-linear decisions, execute API calls, and generate probabilistic outputs.
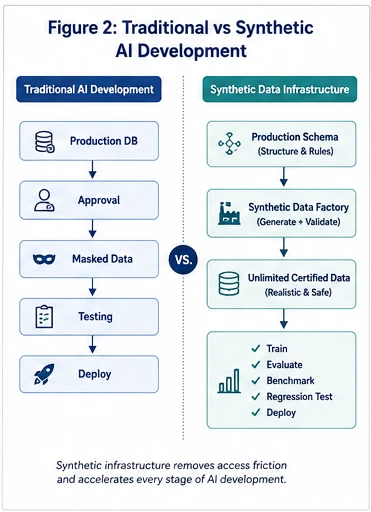
Validating these complex workflows requires thousands of highly realistic, multi-layered scenarios at production scale. Without a continuous supply of high-fidelity data, evaluating an autonomous agent's safety and efficacy becomes impossible, making synthetic data an increasingly critical part of the modern AI engineering stack.
Autonomous agents make non-linear, probabilistic decisions that cannot be validated with static test cases. Verifying agentic behavior requires thousands of high-fidelity, multi-layered scenarios generated at production scale.
What is the Enterprise Data Access Bottleneck?
Enterprise data rarely exists as clean, isolated CSV files. Instead, it lives inside highly normalized relational databases, decades-old legacy systems, and complex enterprise schemas. One of the most challenging examples is the Entity-Attribute-Value (EAV) design pattern, commonly found in enterprise platforms such as Magento and many Electronic Health Record (EHR) systems.
These environments introduce architectural challenges that go far beyond simply replacing or masking sensitive values:
- Fragmentation: Data is fragmented vertically and horizontally across hundreds of interconnected tables.
- Referential Integrity: Relationships span dozens of tables and must be maintained perfectly to prevent system crashes.
- Embedded Logic: Business logic is frequently embedded within the schema design rather than the application code.
- Semantic Correlations: Statistical relationships between attributes must remain entirely realistic.
- Domain Constraints: Domain-specific constraints must always hold true.
For example, generating a synthetic patient with a "Pregnancy" diagnosis while simultaneously assigning biologically incompatible characteristics produces statistically plausible records that are operationally invalid. Similarly, generating synthetic financial transactions without preserving the relationships between customers, accounts, invoices, payments, and balances quickly produces data that breaks downstream applications.
The Audit Note: Validating synthetic EAV structures requires compiling vertical attributes into a virtual wide table to check joint probability distributions before verifying foreign key referential integrity at the database layer.
Creating useful synthetic data therefore requires understanding both database structure and business semantics.
Relational structures like Entity-Attribute-Value (EAV) models distribute business logic vertically. Synthesizing these environments requires preserving statistical correlations and domain constraints across dozens of fragmented tables.
Architectural Blueprint for High-Fidelity Synthetic Data
Building enterprise-grade synthetic data is not a job for a single machine learning model. It is an engineering pipeline composed of multiple specialized stages that together preserve privacy, structural integrity, and business realism.
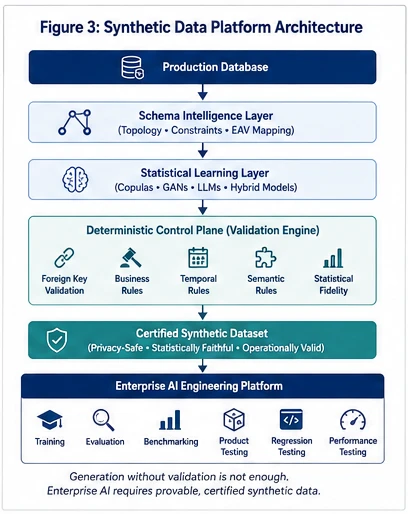
The most important architectural insight is that generation alone is insufficient. Enterprise AI requires an additional deterministic control layer that proves the generated data is fit for purpose.
Generative models are probabilistic, but enterprise databases are deterministic. A robust synthetic data architecture must pair statistical generation with a deterministic control plane that enforces referential integrity and schema rules.
Phase 1: Schema Discovery & Topological Mapping
Before generating a single synthetic record, the system must understand how the database is organized. Rather than focusing on individual tables, the pipeline treats the database as a graph where tables become nodes and foreign keys define relationships. This graph determines the exact order in which synthetic entities must be created.
Complex EAV schemas introduce additional challenges because meaningful attributes are distributed vertically across metadata and value tables. To preserve correlations, the pipeline first constructs temporary analytical views that transform fragmented EAV structures into virtual wide tables, allowing downstream models to learn relationships between attributes that never physically exist together.
Phase 2: Statistical and Semantic Generation
Different data requires different generation techniques. No single model performs well across every enterprise dataset.
| Data Type | Preferred Techniques |
|---|---|
| Relational Tabular Data | Copulas, Bayesian Networks |
| Highly Categorical Enterprise Data | CTGAN and Tabular GANs |
| Unstructured Text | Large Language Models (LLMs) |
| Time-Series Data | Specialized sequence models |
| Mixed Enterprise Environments | Hybrid pipelines |
Copulas are particularly effective for structured enterprise databases because they learn the statistical relationships between multiple columns simultaneously—not just each column in isolation. This means that when you generate a synthetic customer record, the income, credit score, and loan amount all move together in realistic ways, not as random, independent numbers.
Conditional GANs complement this by handling datasets with thousands of possible category combinations—the kind of complexity common in enterprise product catalogs, healthcare codes, or insurance classification systems.
Large Language Models become valuable for synthesizing unstructured content such as physician notes, customer service conversations, or underwriting comments. The strongest enterprise architectures increasingly combine these techniques rather than relying on any single model family.
To enforce privacy, the system applies Differential Privacy during model training. The practical result: the generator is deliberately trained with a small, calibrated amount of statistical noise so that no single real customer record can be reverse-engineered from the synthetic output. The organization controls exactly how much privacy protection to apply versus how much statistical accuracy to retain—a tunable dial rather than an all-or-nothing choice.
Phase 3: The Deterministic Control Plane
This is where enterprise synthetic data systems distinguish themselves from research projects. Generative models are probabilistic; enterprise software is deterministic.
After data generation, every synthetic dataset must pass through a validation control plane responsible for enforcing rules that statistical models cannot guarantee. This layer verifies:
- Referential integrity across every single table.
- Primary and foreign key consistency.
- Temporal relationships (e.g., ensuring shipping dates occur after order dates).
- Domain-specific business rules and cross-table semantic consistency.
- Statistical fidelity against production distributions.
Rather than asking whether synthetic data "looks realistic," organizations must ask whether it can prove it satisfies the operational requirements necessary for downstream AI systems.
The Audit Note: The deterministic validation engine runs business logic checks—for example, confirming that shipping dates always follow order dates—before certifying the dataset. No synthetic record is passed downstream until all such rules are programmatically verified.
Phase 4: Downstream Integration & Continuous Evaluation
Once certified, the synthetic data is routed to evaluation harnesses and regression test suites. This integration ensures that the evaluation pipeline remains active and continuously fed with high-fidelity, edge-case data. Testing is never a static snapshot; it must scale alongside the software update cycle.
Why AI Product Leaders Should Care
Synthetic data changes far more than engineering productivity; it fundamentally transforms product strategy. Future enterprise AI spending will focus heavily on evaluation infrastructure rather than foundation model training. For an AI product leader, managing an application without a high-fidelity synthetic data pipeline is the equivalent of flying blind.
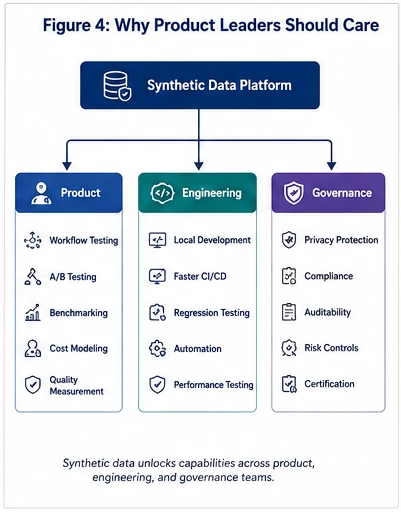
Synthetic data gives product teams the same kind of reproducible experimentation platform that automated testing gave traditional software. It unlocks five critical product capabilities:
- Risk-Free Workflow Validation: Product teams can completely validate new, autonomous AI workflows, prompt strategies, and agentic steps against realistic data ecosystems before ever exposing actual customers to the live model.
- True A/B Evaluation: Teams can run parallel evaluations of different model variants, system prompts, or RAG configurations using identical, controlled datasets to isolate true performance gains.
- Vendor & Model Benchmarking: When upgrading from one model generation to the next, or evaluating an open-weights model against a proprietary API, synthetic pipelines allow product leaders to run automated regression testing to spot hidden regressions.
- Unit Economic Estimation: By running production-scale synthetic workloads through an application pipeline, product managers can accurately estimate token usage, compute latency, and ongoing operating costs before launching a feature.
- Measurable Quality Benchmarking: Product leaders can establish quantifiable baselines to measure drift, accuracy, and compliance across subsequent software releases, transforming qualitative "vibe checks" into hard engineering metrics.
The Audit Note: Unit economic estimation works by running realistic synthetic workloads through the full AI pipeline—capturing input tokens, output tokens, latency, and failure rates—so product leaders can calculate the cost per successful outcome before a single real user is exposed.
Evaluation is the core of AI product strategy. A high-fidelity synthetic data pipeline provides the reproducible playground needed to run regression testing, model benchmarking, and unit economic estimation.
The Architecture of Proof for Synthetic Environments
To safely build and evaluate agentic systems, organizations must adopt an Architecture of Proof for their synthetic data infrastructure. This framework treats synthetic data not as an approximate mock, but as a verifiable engineering asset.
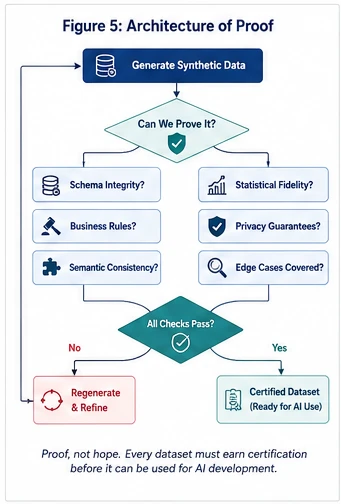
By forcing every synthetic record to prove it conforms to both statistical reality and semantic constraints, the organization creates an uncompromised validation sandbox. This ensures that models are evaluated against realistic, stress-tested environments before they ever touch production.
Synthetic data is not a one-time compliance output; it is a certified engineering asset. Verification must guarantee statistical fidelity, edge-case coverage, and structural compliance before data is served to evaluation pipelines.
From Synthetic Data to Certified AI Development
Generating synthetic records is only half the problem. The harder question — and the one most organizations skip — is: how do you know the synthetic data is actually good enough to trust?
In traditional software, a QA team signs off before a release ships. In enterprise AI, the equivalent gate is data certification. Before any synthetic dataset is routed to an evaluation harness or model training pipeline, it must pass a programmatic certification stage that answers three questions:
- Is it structurally sound? Schema integrity, referential consistency, and business rule compliance are verified record by record. A synthetic portfolio without matching account IDs, or a synthetic patient record with internally contradictory attributes, is worse than no data — it produces false confidence.
- Is it statistically faithful? The distribution of values must closely mirror what engineers would see in production. If the synthetic data doesn't represent realistic edge cases — the rare fraud pattern, the outlier claim, the low-frequency transaction — models trained or evaluated against it will fail silently in the real world.
- Is it fit for the intended workload? A dataset built for fraud detection is not interchangeable with one built for underwriting model evaluation. Certification validates that the dataset matches the specific demands of its downstream use case.
This certification stage is what separates synthetic data as a compliance checkbox from synthetic data as a first-class engineering asset. Organizations that treat it as the former will generate data and hope for the best. Organizations that treat it as the latter will have a reproducible, auditable foundation for every AI evaluation decision they make.
Certified synthetic data is not a privacy workaround. It is a trust primitive — the foundation on which every downstream model evaluation, regression test, and release decision stands.
Operationalizing Enterprise AI Evaluation
Once organizations can continuously generate certified synthetic environments, comprehensive evaluation workflows become repeatable, measurable, and safe.
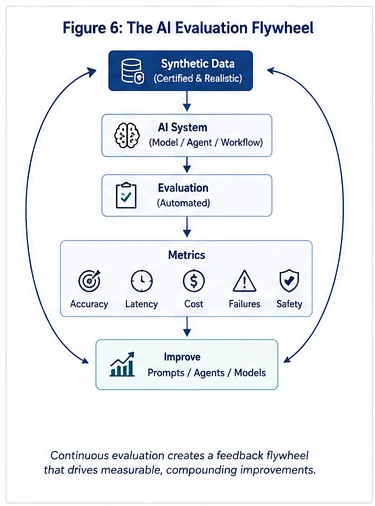
- Commercial Lending: Evaluation teams can generate complex corporate financial portfolios containing intentionally designed anomalies to rigorously test fraud detection models and automated underwriting systems.
- Healthcare: Compliance and product teams can evaluate clinical copilots and automated charting tools using deeply realistic, multi-layered synthetic patient populations without risking PHI exposure.
- Retail: Retail product groups can simulate purchasing behavior, supply disruptions, and inventory anomalies across millions of virtual customers to pressure-test supply chain intelligence models.
From corporate loan anomaly detection to EHR-compliant clinical copilots, synthetic data turns risk-heavy production domains into safe, repeatable evaluation harnesses.
Synthetic Data Is Becoming AI Infrastructure
Synthetic data is no longer simply a compliance or privacy solution—it is rapidly becoming foundational AI infrastructure.
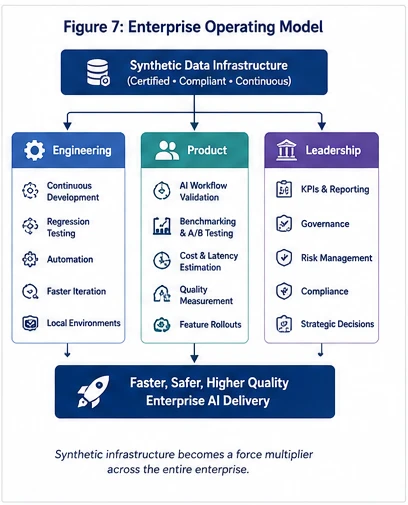
Organizations that can continuously generate realistic, policy-compliant datasets gain an enormous competitive advantage:
- Engineers iterate without waiting months for data approvals.
- Product teams evaluate new AI workflows before customers ever see them.
- Security teams minimize surface exposure to regulated information.
- Legal teams gain stronger, verifiable governance over how AI systems are developed.
- Leadership can measure AI quality using reproducible datasets instead of anecdotal testing.
In other words, synthetic data transforms data access from a governance bottleneck into a scalable engineering capability. The organizations that build this capability first will not simply move faster—they will establish a fundamentally different operating model for AI development.
In the agentic era, competitive advantage does not belong to the largest model. It belongs to the team with the fastest, safest feedback loops. Synthetic data is the infrastructure that drives that speed.
Looking Ahead
Over the next several years, synthetic data platforms will evolve beyond privacy tools into core components of enterprise AI architecture.
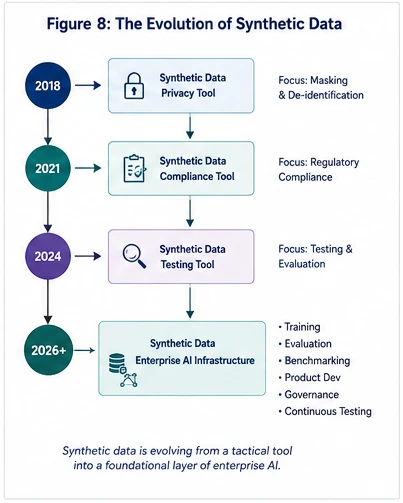
Just as modern software engineering relies on continuous integration (CI/CD), automated testing, and reproducible infrastructure, enterprise AI will increasingly depend on continuously generated, continuously validated synthetic environments.
Model size isn't going to decide or drive success. Success would be decided by how fast the feedback loops run. High-fidelity synthetic data provides those feedback loops by allowing organizations to train, evaluate, benchmark, and improve AI systems continuously while maintaining strong governance and privacy controls.
In the coming years, organizations won't compete solely on model intelligence—they'll compete on the speed, safety, and repeatability of their AI engineering systems. Synthetic data is rapidly becoming one of the foundational layers of that competitive advantage.
One-Line Synthesis
The traditional data strategy of restricting production access is the single greatest bottleneck to enterprise AI; high-fidelity, certified synthetic data is the infrastructure that unlocks rapid evaluation loops and autonomous model execution.
Download the Architecture of Proof Checklist
Ready to implement? Get the definitive checklist for building verifiable AI systems.