The Multi-Agent Illusion: Why More Agents Often Create Less Reliability
The Hidden Cost of Delegation
The original argument for multi-agent systems borrowed heavily from organizational design and distributed systems theory. Specialization improves performance. Parallelization improves speed. Delegation improves scale.
In theory, that logic is sound.
But AI agents are not deterministic software components. They are probabilistic reasoning systems. They reinterpret context, compress meaning, infer intent, and generate outputs that can vary from run to run. Every handoff between agents therefore becomes more than a task transfer. It becomes a context compression boundary, a trust boundary, and a verification boundary.
That distinction matters enormously.
Human organizations survive delegation because people share institutional context, ask clarifying questions, and escalate ambiguity when uncertainty appears. AI agents do none of that reliably. They can confidently pass along incomplete, distorted, or overly compressed information, and the next agent may reason over that weakened context as though it were authoritative.
The architecture may look modular. Operationally, it behaves more like a chain of probabilistic assumptions.
The Telephone Game Problem
The easiest way to understand multi-agent failure is to think about the childhood game of telephone.
One agent retrieves partial information. Another summarizes it poorly. A third reasons over the summary. A fourth executes the workflow. By the time the task completes, the final output may sound coherent while being fundamentally wrong.
This is what makes multi-agent systems deceptive in practice. They often fail cleanly.
The output looks structured. The agents appear collaborative. The workflow sounds intelligent. Yet the original error may have entered two or three steps earlier, hidden behind layers of plausible intermediate reasoning.
That creates a debugging problem as much as a modeling problem.
In traditional software systems, failures are often traceable to a discrete function, service, or dependency. In multi-agent systems, failures diffuse across delegation chains. Once context degrades across several hops, the true source of failure becomes difficult to isolate. Teams end up investigating symptoms instead of causes.
The more agents you add, the harder it becomes to answer a very simple operational question:
Where exactly did reality diverge from the workflow?
The Coordination Tax
Multi-agent systems introduce what can best be described as a coordination tax.
Each additional agent increases the operational burden of keeping context synchronized, maintaining memory consistency, validating intermediate outputs, and localizing failures when the workflow breaks.
At small scale, this cost is easy to ignore. At production scale, it becomes structural.
This is why many teams discover that multi-agent architectures behave less like parallel compute systems and more like complex management hierarchies. The system spends increasing amounts of effort coordinating itself rather than performing useful work.
Instead of reducing operational load, the architecture often creates:
- review queues,
- reconciliation logic,
- retry chains,
- verification layers,
- orchestration overhead,
- and fallback workflows that quietly erase the original efficiency gains.
The deeper issue is conceptual.
AI teams often treat agents like interchangeable workers. But agents are not workers in the traditional sense. They are probabilistic reasoning engines. Every delegation boundary introduces uncertainty. Once those boundaries multiply across a workflow, uncertainty compounds operationally.
This is not merely an engineering concern. It becomes an economic one.
The organization eventually pays for coordination through additional oversight, verification labor, observability tooling, and recovery workflows.
Mathematical Proof of Reliability Decay
To understand why this happens, we can model the reliability of sequential agent handoffs mathematically.
Let the reliability of an individual probabilistic agent executing a subtask be represented by $p$, where $0 < p < 1$. In a sequential chain of $n$ independent probabilistic agents, each passing context to the next, the end-to-end reliability of the system $R$ decays exponentially:
$$R = p^n$$
This decay shows that as $n$ increases, the probability of system-wide success drops sharply. For example, if we have highly accurate agents that are individually $95\%$ reliable ($p = 0.95$):
- A short chain of $n = 2$ agents has an end-to-end reliability of $R = 0.95^2 \approx 90.2\%$
- A chain of $n = 4$ agents has an end-to-end reliability of $R = 0.95^4 \approx 81.4\%$
- An unconstrained swarm of $n = 8$ agents drops overall system reliability to a mere $R = 0.95^8 \approx 66.3\%$
This exponential decay is the mathematical explanation for the Telephone Game problem. Every context compression and handoff boundary compounds the underlying probabilistic error rate of the models, translating architectural sophistication into operational fragility.
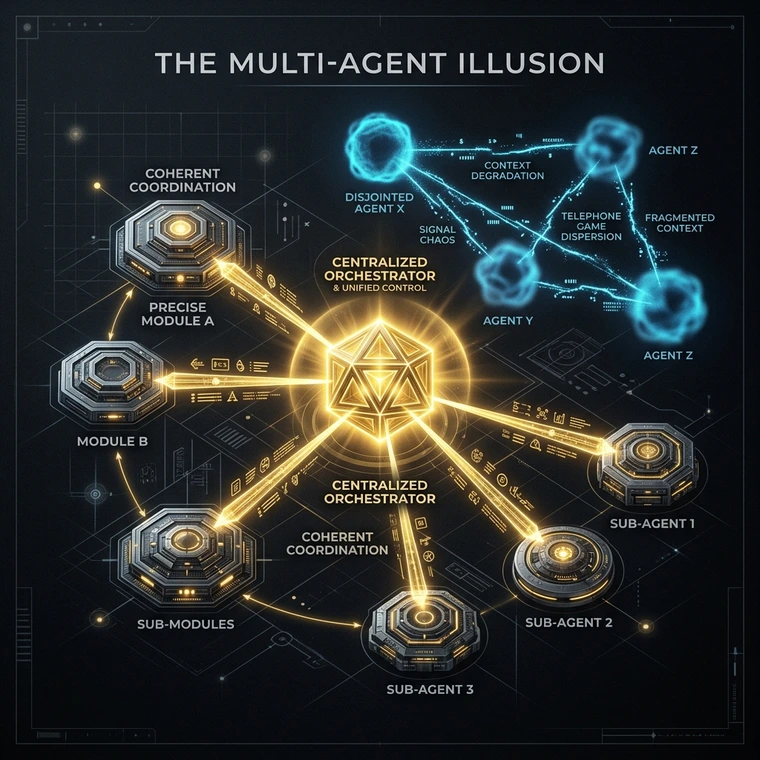
Why Does Centralized Reasoning Often Win?
This is one reason centralized orchestration continues to outperform unconstrained agent swarms in many production systems.
A centralized reasoning loop preserves context continuity, memory consistency, and accountability. The system may still call tools, retrieve information, or execute specialized subtasks, but the core reasoning process remains unified.
That matters because coherence is often more valuable than specialization.
A single orchestrator maintains one evolving representation of the task, one decision context, and one accountability chain. Failures are easier to trace. Verification becomes simpler. State management becomes more reliable.
This does not mean multi-agent architectures are always wrong. It means the additional complexity is only justified when the workflow genuinely benefits from parallel specialization without losing coherence.
In practice, many systems add agents before they add proof mechanisms, observability, or reliable coordination structures. The architecture becomes sophisticated faster than it becomes trustworthy.
That is why the critique of unconstrained multi-agent systems has aged surprisingly well. The important insight was never that multiple agents are inherently bad. The insight was that context fragmentation destroys reliability faster than most teams expect.
Where Do Multi-Agent Systems Actually Work?
Multi-agent systems do have legitimate strengths.
They work best when tasks are separable, outputs are independently verifiable, and partial failure is acceptable.
Research workflows are a good example. One agent can search sources while another synthesizes findings. Parallel retrieval systems also work well because each agent gathers different slices of information that can later be merged and validated.
Document classification systems are another strong fit because outputs are bounded and relatively easy to evaluate after the fact. Bounded monitoring systems also benefit from specialization because different agents can independently inspect different operational signals.
Coding environments sometimes benefit as well, particularly when subtasks are isolated and interfaces are clearly defined.
The common thread across successful multi-agent deployments is not intelligence. It is boundedness.
The tasks are modular enough that context degradation does not become catastrophic.
Where Do They Break Down?
The risks rise sharply in workflows that require deep shared context, persistent memory, or tightly coupled reasoning.
Healthcare authorization is one example. A retrieval agent may summarize patient history incorrectly. A reasoning agent may interpret the summary confidently. An execution agent may trigger an authorization decision based on flawed context. The workflow appears coherent while quietly drifting away from reality.
The same pattern appears in finance, legal systems, enterprise operations, and compliance workflows.
These environments depend on coherent reasoning across multiple interconnected steps. If one agent distorts a detail, another may amplify the distortion, and a third may operationalize the error with confidence.
At that point, the problem is no longer model quality alone.
It becomes a systems coherence problem.
And coherence is far harder to preserve across loosely coupled agents than across a centralized reasoning structure.
The Illusion of Sophistication
One reason multi-agent systems spread so quickly is that they look advanced.
A dashboard showing agents planning, delegating, debating, and coordinating feels impressive. It creates the visual impression of intelligence scaling through collaboration.
But architectural sophistication and operational reliability are not the same thing.
In many cases, agent swarms create the illusion of robustness while actually increasing fragility underneath. More agents mean more prompts, more routing logic, more memory synchronization, more failure surfaces, and more hidden assumptions about context continuity.
Complexity compounds invisibly until the system reaches production scale.
Then the organization discovers that it has built a distributed reasoning system that is difficult to debug, expensive to verify, and increasingly hard to trust.
The Product Lesson
For product teams, the big question is not how many agents to use. It's where context must remain unified and where it can safely fragment.
Every delegation boundary creates operational risk, verification cost, and accountability complexity. That means architecture decisions increasingly become product decisions because they shape not only capability, but also reliability, trust, auditability, and the economics of operating the system at scale.
This is the deeper lesson many teams miss.
Instead of building agent swarms or the most visually impressive orchestration layers build systems that know:
- when to delegate,
- when to centralize,
- where proof is required,
- and how to preserve coherence while still benefiting from specialization.
The competitive advantage shifts away from raw orchestration complexity and toward operational trust.
A Better Design Principle
A more durable design principle is surprisingly simple:
- Keep the reasoning loop centralized.
- Delegate only when the boundary is clear.
- Avoid agent sprawl unless it creates measurable value.
- That framing changes the goal entirely.
- Instead of asking “How many agents can we coordinate?”, ask “How much delegation can the system absorb before trust begins to degrade?”
That is a much more operationally honest way to think about agentic systems.
The Audit Note: A centralized coordinator with a deterministic schema and formal validation boundaries provides a verifiable state trace. By binding each external agent tool-call to a cryptographic causal trace, we can achieve $100\%$ post-execution replayability, neutralizing the cascading uncertainty of probabilistic pipelines.
The Bottom Line
The multi-agent debate is ultimately a systems design lesson, not just a model design lesson.
More intelligence does not automatically create more reliability. In many cases, it does the opposite.
As AI systems become more autonomous and more distributed, the true competitive advantage shifts toward:
- coherence,
- verification,
- context continuity,
- observability,
- and operational trust.
That is the real lesson behind the multi-agent illusion.
Coordination is not free. Delegation is not neutral. And more agents often create more places for reality to drift apart.
Simple systems are frequently more reliable than clever ones, especially when trust, accountability, and correctness matter.
Download the Architecture of Proof Checklist
Ready to implement? Get the definitive checklist for building verifiable AI systems.