The Correlation Problem: Why Pattern-Matching AI Can't Be Governed — Only Monitored
Most enterprise AI governance programs are built on a flawed assumption.
The assumption is that a model becomes governable once you add monitoring, audit trails, and escalation protocols around it. If the model misbehaves, the monitoring layer catches it. If the audit trail is complete, you can explain what happened. If escalation protocols are in place, a human takes over.
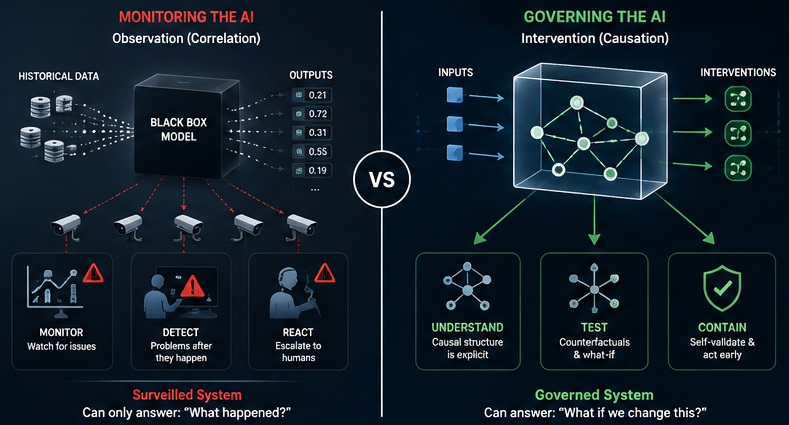
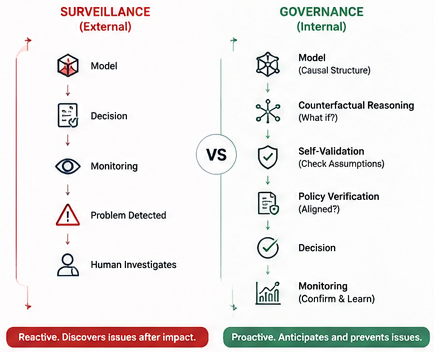
That architecture is better than nothing. But it is not governance. It is surveillance.
The difference between surveillance and governance is the question you can answer from the inside of the system, without waiting for something to go wrong.
A governed system can answer: "If we change this input, what will the output become?" A surveilled system can only answer: "Here is what the output was last time."
Nearly every correlation-based AI model in production today requires external surveillance to compensate for its inability to reason about interventions. That is the correlation problem.
The Audit Note on "Proof": In the context of the Architecture of Proof, "proof" does not refer to absolute mathematical certainty. Rather, it denotes reproducible evidence obtained through intervention-aware reasoning — the programmatic ability to demonstrate why a decision occurred and how it would respond to structural changes.
What Correlation-Based Models Actually Learn
To understand the governance ceiling, you have to be precise about what a statistical model does.
A model trained on historical data learns the association between input features and output labels as those associations existed in past observations. Given enough data and the right architecture, it learns these associations with impressive fidelity. That is why models predict fraud, classify documents, score creditworthiness, and route support tickets with meaningful accuracy.
But there is a precise boundary to what historical association can tell you, and that boundary has a name in the formal literature: the difference between observation and intervention.
Observation answers: "In the past, when X was true, Y followed." Intervention answers: "If I change X right now, what will Y become?" These are structurally different questions. Correlation answers the first. It cannot answer the second.
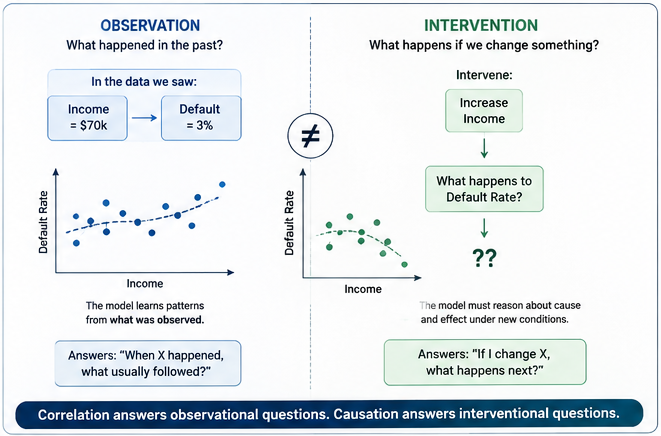
This distinction was formalized by Judea Pearl in his work on causal inference, but the practical implication for AI governance is immediate and operational: a model that can only answer observational questions cannot be steered. You can watch it. You cannot reason about what it will do next when conditions change.
The Three Questions That Expose the Ceiling
There are three governance questions that every enterprise AI deployment eventually faces. Correlation-based models cannot answer any of them from the inside.
Question 1: If we change this policy, what will the model do?
A lender changes its underwriting policy — say, increasing the minimum income threshold. The correlation-based model was trained on historical data from before that change. The historical association between income level and default probability holds under the old policy regime, not the new one. The model has no internal mechanism to reason about the policy change. It continues generating predictions using patterns that are no longer valid.
You discover this through monitoring — by watching outcomes degrade — not through any reasoning capability in the model itself.
Question 2: Why did this specific decision happen?
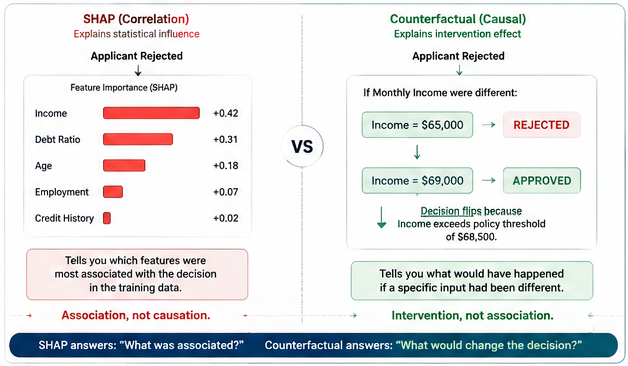
Post-hoc explainability tools like SHAP produce feature importance scores. They tell you which inputs had the highest statistical weight on the output. That is correlation — the inputs that most closely track the output in the model's learned representation.
Feature importance is not causation. A high SHAP value for a feature does not mean that feature caused the decision. It means the feature was statistically associated with the decision in the training data. In a regulatory context — adverse action notices in lending, clinical audit trails in healthcare, anti-discrimination requirements in insurance — explaining statistical influence (e.g., via SHAP) is increasingly falling short of demonstrating causal impact. Courts and regulators increasingly demand causal reasoning to explain intervention effects rather than relying on statistical correlation alone.
The Audit Note: The difference between SHAP and a causal trace is not a matter of technical sophistication. It is a distinction of actionability. SHAP says "these features moved together with this outcome in training." A causal trace says "this feature, at this value, caused this decision to flip." The latter provides the direct interventional mapping that high-stakes regulatory environments increasingly demand.
Question 3: Is the model still valid today?
Model drift detection works by monitoring statistical distributions over time. If the input distribution shifts beyond a threshold, an alert fires. That is again observation — watching what the inputs look like rather than understanding the model's behavior under those new conditions.
A model can pass all drift detection thresholds while being completely invalid for the current environment. The historical correlations it encoded may no longer reflect real-world causal relationships. You find out not because the model tells you, but because outcomes degrade and the monitoring system catches the signal — often weeks after the damage began.
Why This Creates an Irreducible Verification Burden
The three questions above are not edge cases. They are the routine operational questions of any AI deployment that runs for more than a few months.
Because correlation-based models cannot answer them from the inside, every organization that deploys them must build an external verification apparatus to compensate. This is the pattern described in The Hidden Tax of Low-Trust AI: the verification spiral. Review queues, reconciliation logic, manual spot-checks, compliance audits, and escalation workflows that exist not because the business chose them, but because the system is structurally incapable of reasoning about its own validity.
The verification burden on a correlation-based model is not a product design failure. It is an architectural consequence. You are paying, in operational labor, for the reasoning capability the model does not have.
The cost is real and measurable. An organization running a correlation-based model in a regulated environment carries:
- Ongoing drift monitoring to detect when historical associations break down
- Manual review queues for decisions that produce high-confidence outputs on low-confidence grounds
- Post-hoc explainability labor when a decision is challenged and the model cannot explain itself
- Periodic retraining cycles triggered by monitoring signals rather than by any internal validity check
- Regulatory response overhead when the statistical nature of the explanation proves insufficient for the auditor
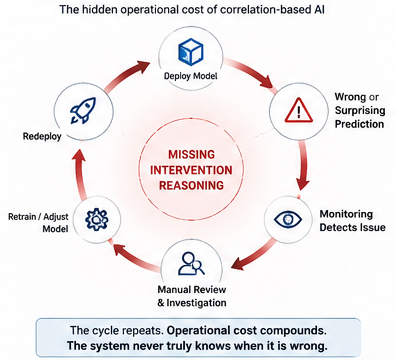
None of these costs appear in the original ROI model. All of them appear in the operating model by the time the system reaches production scale.
A Concrete Comparison: Explainability vs. Intervention
To understand the difference in practice, consider a lending decision where an applicant is rejected.
It is worth noting upfront: counterfactuals can be generated from correlation-based models too — tools like DiCE and Wachter et al. do exactly that. The critical distinction is not whether a counterfactual exists, but whether it respects the causal constraints of the real world — whether it only proposes interventions the applicant can actually make.
The Correlation-Based Explanation (SHAP):
Applicant rejected.
SHAP Feature Contribution:
- Monthly Income: +0.42
- Debt-to-Income Ratio: +0.31
- Length of Employment: +0.21
What this tells you: These features had the highest statistical weight in the model's output. It does not tell you whether changing any one of them would actually flip the decision, nor does it distinguish between features the applicant can change and features they cannot.
The Unconstrained Counterfactual (from a correlation-based model):
Applicant rejected.
Counterfactual:
- If Age decreased by 6 years AND Employment history increased by 3 years,
the application would have been approved.
The problem: Age cannot be decreased. This counterfactual correctly identifies where the model's decision boundary sits, but proposes an intervention that is physically impossible. It tells you about the model's surface, not what the applicant can actually do.
The Causal Counterfactual (constraint-respecting):
Applicant rejected.
Causal Counterfactual (constrained to actionable interventions):
- If Monthly Income increased by $400 while existing debt remained unchanged,
the application would have been approved.
- This intervention is feasible, financially consistent, and respects the
directional causal relationships encoded in the model structure.
What this tells you: A decision boundary constrained to what is actually changeable. The applicant gets actionable recourse. The regulator gets a trail grounded in causal structure, not statistical boundary-seeking. That constraint is the product of having a causal graph — a model of which variables can influence which, and in what direction.
The Causal Alternative: Governance From the Inside
This distinction produces a qualitatively different kind of system.
| Capability | Correlation Model | Causal Model |
|---|---|---|
| Answers observational questions | Yes | Yes |
| Answers interventional questions | No | Yes |
| Supports counterfactual proof | No | Yes |
| Supports structural testing | No | Yes (via causal drift validation) |
| Produces defensible explanations | No | Yes |
| Governance mechanism | External surveillance | Internal verification |
The key phrase in that table is "internal verification." Because causal models explicitly encode assumptions about causal structure, those assumptions can be directly tested against incoming observational and interventional data as it arrives. When these causal assumptions are violated, the system can flag structural drift before the downstream predictive accuracy collapses. This is the mechanism behind Causal Drift detection described in Stage 4 Maturity.
A correlation-based model fails silently when underlying relationships shift, remaining dependent on external outcomes monitoring. A causal system allows for testing of structural assumptions, enabling proactive detection and containment. That difference determines whether your governance program is proactive or reactive.
Counterfactual testing is the operational expression of this capability. When a lending model rejects an application, a causal model can answer: "If the applicant's bank statement gap had been zero days instead of forty-seven, would the decision have flipped?" That is a counterfactual test, not an estimate. It is a statement about what the system would have done under different conditions — and it is legally defensible in a way that feature importance scores are not.
The Prerequisite Problem for Layer 6
The Architecture of Proof framework defines Layer 6 as Causal Diagnostics and Remediation — the capability to run 4-minute root cause analyses using causal traces and counterfactual tests. It is the incident response layer.
But Layer 6 has a prerequisite that the framework does not state explicitly: the upstream model must have been built causally for the causal trace to contain meaningful information.
A correlation-based model produces an audit log, not a causal trace. The audit log records what inputs entered, what the model's internal activations were, and what output emerged. If you replay that log, you learn what happened — you do not learn why it happened in any causal sense, and you cannot use it to answer what would have happened under different conditions.
The 4-minute RCA works because it replays a causal structure, not a data sequence. It answers: "This feature caused this decision to flip at this confidence threshold." That statement requires the model to have encoded causal relationships in the first place.
Audit trails without causal structure are forensic archaeology. You can reconstruct the sequence of events, but you cannot prove the mechanism. Causal traces let you run the experiment you didn't run. That is the difference between evidence and proof.
This is where the correlation problem intersects with governance maturity. Organizations at Stage 2 and 3 — Replayable Evidence and Controlled Autonomy — may have sophisticated audit trails and escalation protocols. But if the underlying models are correlation-based, the audit trails cannot support the causal reasoning that Stage 4 requires. The governance ceiling is set not by the observability infrastructure, but by the internal structure of the model.

The Product Implication
For AI product managers, the correlation problem reframes the governance question from a compliance checklist to an architectural decision.
The question is not "Do we have monitoring?" The question is: "Does our model have the internal structure to reason about interventions — or are we permanently dependent on external observation to catch what the model cannot tell us itself?"
This is not an argument that causal models are easy to build. Specifying a valid causal graph — the directional structure of which variables influence which — requires genuine domain expertise, and that structure can itself be wrong. Causal discovery algorithms exist to help infer structure from data, but they carry their own assumptions and fail under certain data conditions. The honest case for building causally is not that it costs less upfront. It is that the verification burden of a correlation-based model at regulated scale eventually exceeds the construction cost. The question is not whether to pay — it is when, and in what form: domain expert time during design, or operational labor compounding indefinitely in production.
The practical implication is phased:
At design time: Ask whether the domain requires answers to interventional questions. Lending, healthcare, insurance, fraud, and compliance almost always do. If the answer is yes, a correlation-based model is structurally insufficient — regardless of its accuracy on held-out data.
At build time: Require that the model's architecture encode directional relationships between variables, not just statistical associations. This is the difference between a model that learns from data and a model that learns the structure of the world from data.
At deployment time: Evaluate governance readiness not by monitoring coverage but by counterfactual capability. Can the model answer what would have happened if a specific input had been different? If not, the governance program is surveillance, not proof.
At scale: Recognize that the operational cost of a correlation-based model grows with deployment scope. Every new regulated domain, every new jurisdiction, every new audit requirement adds to the external verification burden. The causal alternative reduces that burden by moving verification capability inside the system.
The governance ceiling of a correlation-based model is not a model quality problem. It is a structural one. You cannot audit your way to causal proof. You have to build the causal structure in.
What This Changes in Practice
Replacing correlation with causation is not a one-shot architectural migration. It is a design commitment that surfaces in specific, concrete decisions.
It surfaces when you decide whether a model needs to produce an explanation or a proof for a challenged decision.
It surfaces when you define what "model drift" means — whether it means the input distribution shifted or whether it means the causal relationships the model depends on have changed.
It surfaces when you scope a regulatory response — whether you are presenting statistical feature importance or a counterfactual test that demonstrates exactly why the decision was made and what would have changed it.
It surfaces when you design the escalation boundary — whether human review is triggered by a confidence threshold on a correlation-based output, or by a detected violation of a causal assumption that the model itself can identify.
In each case, the correlation-based answer is available faster, is easier to implement, and is cheaper in the short term. The causal answer is the one that holds up in an audit, under cross-examination, and at production scale when the world has changed.
Correlation scales faster. Causation governs longer. For systems that need to operate in regulated environments for years, not sprints, the architectural choice is clear.
One-Line Synthesis
Correlation-based models learn historical associations. Causal models reason about how interventions change outcomes. That distinction determines whether an AI system can merely be monitored—or can participate meaningfully in its own governance.
Download the Architecture of Proof Checklist
Ready to implement? Get the definitive checklist for building verifiable AI systems.