Explainability vs. Traceability: Why AI Teams Confuse Them and How It Costs You | AI Governance
This post is part of the Decision Traceability pillar.
Of all the terms in AI governance, explainability and traceability are the most frequently used as synonyms. They are not synonyms. They answer different questions, serve different purposes, and their confusion produces governance architectures that look robust until the moment they need to work.
This post defines both precisely, explains where each is useful and where each fails, and argues for why regulated AI systems need both — not one in place of the other.
What explainability is
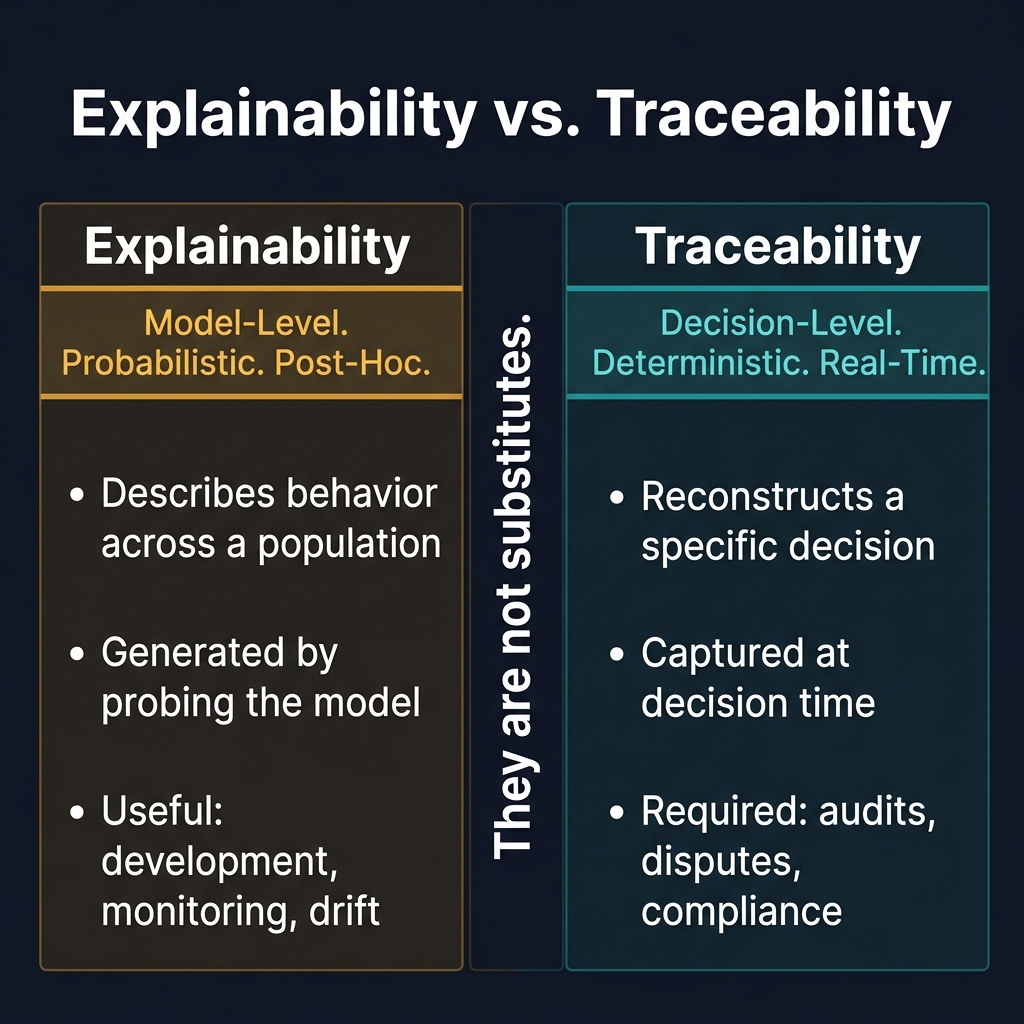
Explainability is the discipline of making a model's decision behavior understandable.
It answers questions like: - Which features did the model weight most heavily across a population of decisions? - Why does this model tend to score cases in segment X higher than segment Y? - What are the dominant patterns the model has learned from the training data?
Explainability tools — SHAP, LIME, integrated gradients, attention visualization — produce interpretations of model behavior. They are generated by probing the model, either at a specific input or across a distribution of inputs, and summarizing what the model's learned function appears to weight.
Explainability is valuable for: - Model development and feature selection - Population-level fairness analysis - Communicating model logic to non-technical stakeholders - Identifying model drift when behavior changes
What explainability is not
Explainability does not reconstruct a specific decision. This is the critical distinction.
A SHAP explanation tells you: "Across similar cases, the model tends to weight income stability heavily." It does not tell you: "For application #7782 submitted on March 15 at 09:42, the model scored 0.31 because these specific inputs were provided and the model version in use at that time weighted these features as follows."
The gap matters in three specific situations:
Regulatory adverse action responses. Consumer protection law requires that an adverse action notice reference the actual factors that drove the specific decision received by the specific individual. A generic model explanation does not satisfy this requirement. If the model has been retrained since the decision was made, a post-hoc SHAP explanation may produce a different answer than the original model would have produced.
Audit reconstruction. When a regulator asks: "Show me the basis for this specific credit decision made 18 months ago," the answer must reference the decision at the time it was made — not what the current model would say about that input.
Incident diagnosis. When a model has been running incorrectly for two weeks, you need to know what specifically changed in the decision-time context. A model explanation tells you about the model's current behavior. A trace tells you what the system actually computed during those two weeks, on those specific inputs, with that specific model version.
What traceability is
Traceability is the ability to reconstruct a specific decision after the fact — including the exact inputs, the rules that fired, the model version and score, and any human intervention — from a record created at decision time.
It answers questions like: - What inputs did the system actually use for decision #7782? - Which rules fired — and which didn't — before the model was called? - What exact score did the model produce, and what version of the model was running? - Who reviewed this case, what did they see, and what did they decide?
Traceability is not a model interpretation. It is a system record.
The evidence captured must be: - Created at decision time — not generated retroactively by re-running the model - Immutable — not alterable after the fact - Complete — covering inputs, rules, model, and human actions - Linked to outcome — connected to what happened after the decision was made
Where each one works and where each fails
| Need | Explainability | Traceability |
|---|---|---|
| Understand model behavior across a population | ✅ Effective | ❌ Not designed for this |
| Detect feature drift in a model | ✅ Effective | ❌ Not designed for this |
| Reconstruct a specific past decision | ❌ Cannot reconstruct | ✅ Designed for this |
| Respond to an individual adverse action complaint | ❌ Insufficient | ✅ Required |
| Answer a regulatory audit on a specific decision | ❌ Insufficient | ✅ Required |
| Diagnose an incident that ran for two weeks | ❌ Shows current model, not past | ✅ Shows what ran at that time |
| Train new team members on model logic | ✅ Effective | ❌ Too granular |
| Monitor fairness at segment level | ✅ Effective | ✅ Effective (from outcome linkage) |
The common mistake: using explainability as a substitute for traceability
The mistake looks like this: an organization invests in SHAP explanations for their production models, builds dashboards showing feature importance, and treats this as their governance story.
When a regulator asks for the basis of a specific lending decision: - The model has been retrained twice since the decision was made - The SHAP values on the current model produce different rankings from the model used at decision time - There is no record of which model version was running when the decision was made - There is no record of which exact inputs the model received
The explainability investment is present. The traceability is absent. The governance architecture fails at the moment it is tested.
Why you need both
Explainability and traceability are complementary, not competing.
Explainability tells you whether your model is behaving as expected across the population. It is a model health and development tool.
Traceability proves that any specific decision was made correctly, within the rules and contracts you defined. It is a governance and compliance tool.
A system with only explainability can describe its model but cannot reconstruct its decisions.
A system with only traceability can prove individual decisions but cannot explain population-level patterns or detect subtle drift.
Production AI systems in regulated industries need both. Explainability tools for model monitoring. Traceability infrastructure for decisions.
What this requires technically
For explainability: SHAP, LIME, or equivalent integrated into the model serving layer; feature importance tracked over time; drift alerts when population-level explanations shift significantly.
For traceability: A decision log schema capturing inputs, rules, model version, model score, human actions, and outcome — written at decision time, immutable, indexed by decision ID, retained for the regulatory period.
The traceability infrastructure must be designed before deployment. It cannot be retrofitted after the fact, because the records that would make past decisions reconstructable were never created.
Related in this pillar
- Decision Traceability: The full framework for building AI decision traces.
- AI Audit Trails: The technical architecture for replayable AI decision records.
- Lending AI Governance: A case study showing where the explainability/traceability distinction matters most.
Download the Architecture of Proof Checklist
Ready to implement? Get the definitive checklist for building verifiable AI systems.