AI Audit Trails: Replayable AI for High-Stakes Systems | AI Governance
This post is part of the Decision Traceability pillar.
This article explains how to build AI audit trails and decision logs so you can replay decisions and prove what your system knew at decision time—capturing the full decision-time context: inputs, rule firing, model versions, and human overrides needed to pass regulatory and internal audits.
How do you design an AI system for replayability?
Replayable AI is achieved by capturing all decision-time context—inputs, model versions, and rule states—allowing any past outcome to be perfectly reconstructed and audited.
Explainable AI is about making a model's behavior understandable in the moment. It answers questions like "Which features mattered most?" or "Why did this case get a higher score?".
Replayable AI is about making a system's behavior reconstructable after the fact. It answers: "What inputs did the system actually see?", "Which rules fired?", and "Did any human override the result?".
Replayability is what lets you take a past decision, feed the same inputs and models back through, and get the exact same result. That’s the foundation for audits and real accountability.
The End-to-End Decision Timeline
To understand how these components interact at runtime, we can visualize the Decision Assembler Flow. This is the core logic engine that orchestrates deterministic rules, probabilistic models, and human oversight into a single immutable record.
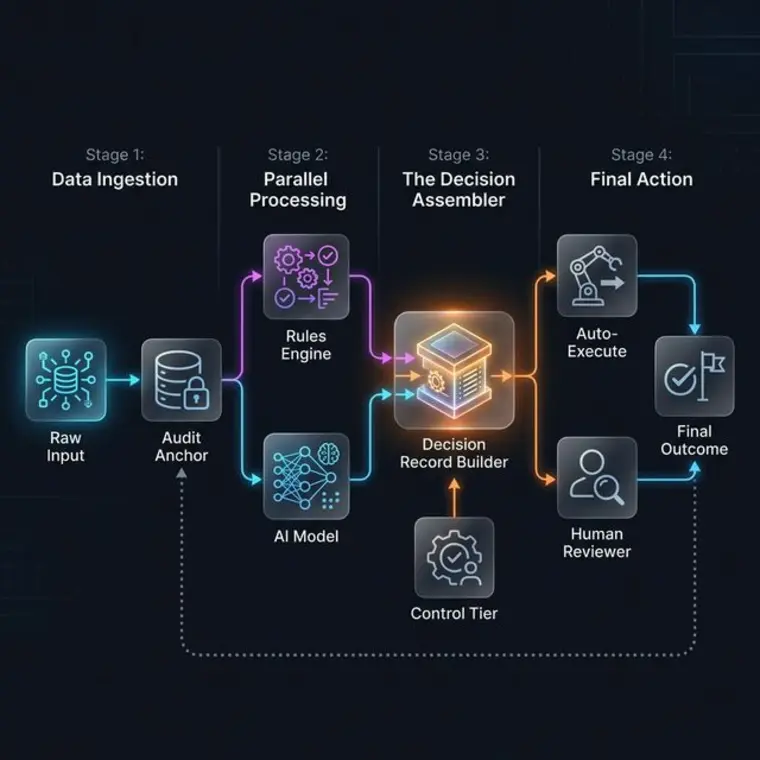
The Audit Note: Every stage of the timeline should be cryptographically linked to the previous one, forming a "Chain of Proof" that makes the entire decision reconstructable in an isolated test environment.
Decision Log Record Anatomy
A mature audit trail is built on "Decision Records"—structured payloads that capture the assembly of a decision at the boundary.

- Header: Decision ID, timestamp, system name.
- Input Block: Key non-sensitive fields stored directly, plus a SHA-256 hash of the full payload and a reference ID pointing to a separate payload store.
- Rules Block: List of rules with true/false results.
- Model Block: Model name, version, and raw score.
- Control Tier: The permissions active at that millisecond.
- Human Block: Reviewer ID and override reason codes.
On Content Hashes: A hash is a one-way tamper seal, not a data replacement. You cannot reverse a hash back to the original data. The correct pattern is a two-part architecture:
- The Audit Record stores key fields + a SHA-256 hash + a
payload_ref_id.- A separate Payload Store (e.g., S3 or a secured DB) holds the full raw inputs, indexed by
payload_ref_id.During debugging, you fetch the raw payload from the Payload Store using the
payload_ref_id, then re-hash it and compare against the stored hash. If they match, the data is provably unaltered. If they don't, you have detected tampering.
Decision Record Framework
| Component | Content | Purpose |
|---|---|---|
| Header | Decision ID, Timestamp, Logic Version | Unique identification and anchoring in time. |
| Input Block | Key fields (direct) + SHA-256 + payload_ref_id |
Direct fields for fast querying; hash + ref for full-data retrieval and tamper detection. |
| Rules Block | Rule Name, Result (Pass/Fail) | Verifying which deterministic constraints were met. |
| Model Block | Model ID, Version, Raw Score, Threshold | Documenting the probabilistic insight delivered. |
| Control Tier | Tier (0-3), Active Permissions | Proving the level of autonomy authorized at execution. |
| Human Block | Reviewer ID, Override Reason Code | Capturing accountability for any manual deviations. |
Why Key Fields + SHA-256 + Ref ID?
Each of the three components serves a completely different purpose. Here is a concrete lending example:
{
"decision_id": "dr-20240315-A7821",
"timestamp": "2024-03-15T14:23:01Z",
"loan_amount": 15000,
"credit_score_bucket": "650-700",
"region": "TX",
"decision": "DECLINED",
"control_tier": 2,
"payload_sha256": "a3f8b2c1d4e5...",
"payload_ref_id": "s3://audit-payloads/2024/03/A7821.json.gz"
}
-
Key fields — for fast, direct querying without ever touching the payload store. > "Show all TX applications with credit score 650–700 that were declined in March" > → Query runs on the audit DB alone. No S3 round-trips. Milliseconds.
-
SHA-256 hash — for tamper detection during a formal audit. > "Prove this record hasn't been altered since it was written" > → Fetch the raw payload via
payload_ref_id, re-hash it, compare topayload_sha256. Match = untouched. No match = evidence of tampering. -
Ref ID — for full reconstruction during regulatory inquiry or model retraining. > "What exact inputs did the model see for application A7821?" > → Fetch
s3://audit-payloads/2024/03/A7821.json.gzand get every feature, field, and raw value.
You only go to the payload store for edge cases — regulatory review, model retraining, or a tamper investigation. For everything else, the key fields are sufficient, which is why costs stay low.
The Difference Between Infra Logs and Decision Logs
While infrastructure logs track system health and performance, decision logs track the logic and sanity of AI-driven outcomes for governance and compliance.
Most teams have great infrastructure logs (latency, CPU, request IDs). These tell you if the system was healthy. Decision logs tell you if the system was sane.
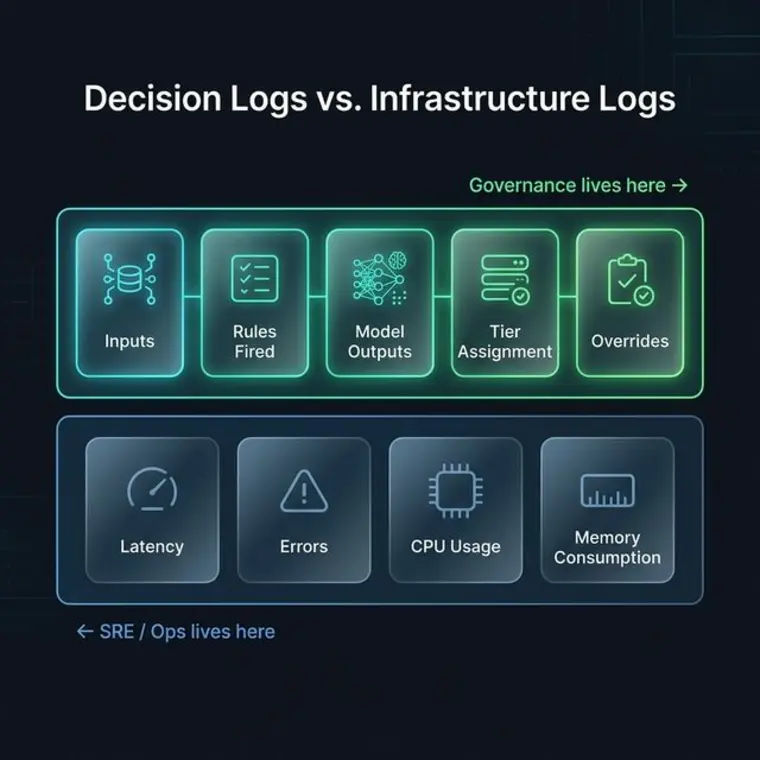
Infra logs live in the SRE world. Decision logs live in the Governance world. You need both to prove that an AI system is operating within its intended guardrails.
Designing for Replayability
Designing for replayability requires a central Decision Log Store and Model Registry that can feed a Replay Engine with the exact state required to reproduce a past decision.
To reconstruct history, you have to design for it up front. This requires a specific architecture where your Decision Log Store and Model Registry can perfectly feed a Replay Engine.
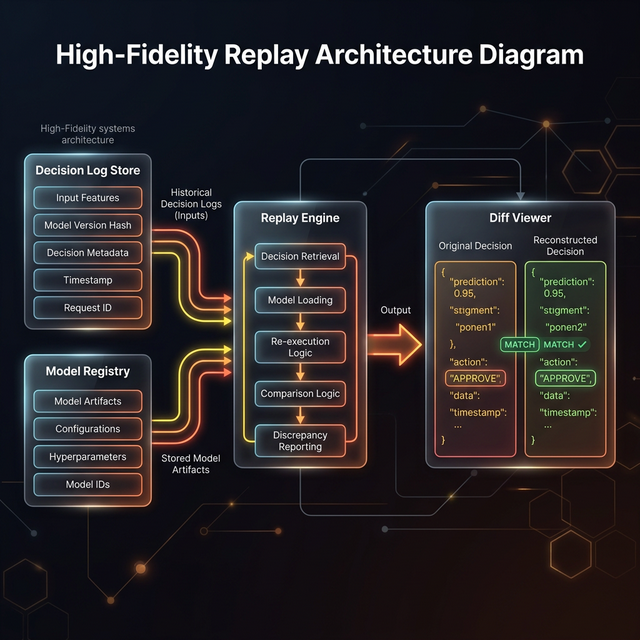
If you can't recreate a past decision exactly in a test environment, your audit trail has a gap.
Making Audit Access a Product
Finally, your audit trails shouldn't be hidden in a database that requires an engineer to query. They should be accessible via a Query Flow designed for risk and compliance users.

This allows non-technical stakeholders to ask questions like "Show all Tier 2 decisions for segment X" or "Show defaults where rules said 'no' but the system approved."
Storage Planning for Audit Records
A well-designed audit trail is small enough to be affordable and structured enough to be queryable — but only if you plan for the two-layer architecture from day one.
Audit storage lives in two distinct layers with very different scaling profiles.
Layer 1: Decision Records
The audit record itself is lean. A compact JSON payload for a single decision is approximately:
| Component | Estimated Size |
|---|---|
| Header (Decision ID, timestamp, logic version) | ~100 bytes |
| Input Block (key fields + SHA-256 hash + ref ID) | ~300 bytes |
| Rules Block (10–20 rule names + boolean results) | ~500 bytes |
| Model Block (model ID, version, score, threshold) | ~200 bytes |
| Control Tier + Human Block | ~150 bytes |
| Total per record | ~1–2 KB |
Annualized storage at different decision volumes:
| System Scale | Daily Volume | Yearly (raw) | Yearly (compressed) |
|---|---|---|---|
| Small team / internal tool | 1K decisions | ~700 MB | ~70–140 MB |
| Mid-size product | 100K decisions | ~70 GB | ~7–14 GB |
| High-frequency (e.g., lending) | 1M decisions | ~730 GB | ~75–150 GB |
Note on compression: Columnar formats like Parquet achieve 5–10x compression on structured audit records, especially on repeated string values like rule names, model IDs, and control tier codes.
Layer 2: Payload Store (Full Raw Inputs)
This is where storage scales fast. Full ML feature vectors or document payloads typically run 20–100 KB per decision:
| System Scale | Avg Payload Size | Yearly |
|---|---|---|
| 100K decisions/day | 50 KB | ~1.8 TB/year |
| 1M decisions/day | 50 KB | ~18 TB/year |
Design choice: If you don't require full replay — only tamper detection — you can store only the hash and skip the payload entirely. This drops Layer 2 cost to zero at the expense of not being able to reconstruct the exact original input.
Tiered Retention Strategy
Hot (0–30 days) → Postgres / DynamoDB Fast queries for live compliance review
Warm (30d–1yr) → S3 + Athena / BigQuery Cheap, still queryable for regulatory requests
Cold (1yr+) → S3 Glacier / Deep Archive Pennies/GB for long-term legal retention
The decision record layer is affordable at any scale. The payload store is where you need a deliberate tiering policy. For most regulated industries, a 3-year warm + 7-year cold retention window covers audit obligations.
Practical Tips for Your Audit Stack
A mature AI system should be able to show its work, prove consistency, and support accountability. This level of detail is exactly how audit trails enable effective AI escalation and provide the evidence needed for Composite Accountability.
Related in this series
- Building Accountability frameworks for AI: See how audit trails anchor system-wide responsibility.
- How AI Systems Ask for Help: Learn how audit logs provide context for automated escalation.
Download the Architecture of Proof Checklist
Ready to implement? Get the definitive checklist for building verifiable AI systems.