Composite Accountability: Proving Each Part of Your AI System Did Its Job | AI Governance
This post is part of the AI Accountability Architecture pillar.
This post explains how to design accountability frameworks for AI systems using rules, models, and humans to ensure every automated decision is defensible.
Most "AI failures" don't come from the model alone. They come from a system where rules, models, and humans are all involved—but when something breaks, nobody can say which part failed or why.
We blame "the AI," roll back a feature, and move on. That isn't governance. It's guesswork in post‑mortems.
Composite Accountability is the idea that in a composite system, every actor—rules, models, and humans—must have a clear contract and a way to prove it kept that contract. A robust decision log is the foundation for reconstructing history and maintaining accountability.
This post is about how to do that.
From composite intelligence to composite accountability
Composite accountability ensures that every component of a multi-actor AI system—rules, models, and humans—has a verifiable contract and clear responsibility for outcomes.
In the previous piece, we looked at composite intelligence: systems where rules, models, and humans work together in one flow, instead of a single model doing everything.
The next step is obvious but rarely done:
If intelligence is composite, accountability has to be composite too.
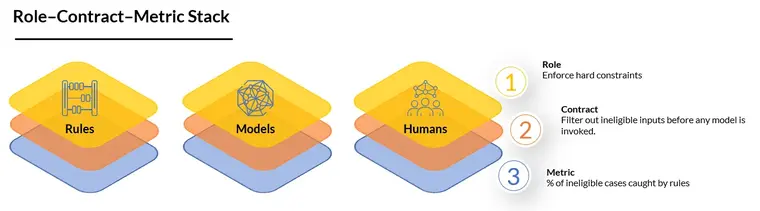
Instead of one big metric like "model accuracy" or "conversion rate," each part gets: - A role (what it is supposed to do) - A contract (what "doing it correctly" means) - A local metric (how you measure that)
When something goes wrong, you don't just know that "the decision was bad." You know whether: - The rules fired correctly - The model behaved as designed - The human followed policy - Or the orchestration between them was flawed
That's the heart of composite accountability.
What are the roles in a composite AI system?
A composite AI system assigns specific responsibilities to each actor: rules enforce invariants, models provide probabilistic insights, and humans handle complex judgment.
Start by being explicit about what each actor is responsible for in the flow.
For a lending or fraud decision, that might look like this:
Rules
- Enforce hard constraints (eligibility, regulatory limits, safety checks).
- Decide when the model is even allowed to run.
- Decide when a human must be involved.
Models
- Score risk, probability, similarity, or intent.
- Rank or cluster items.
- Provide estimates, not final verdicts.
Humans
- Handle edge cases and gray areas.
- Make exceptions and tradeoffs under policy.
- Own the final approval in certain bands.
If you can't describe each role in concrete language, you can't hold it accountable later.
Step 2: Write local contracts
Next, turn roles into contracts—simple, testable statements about what each part must and must not do.
Rules contract
- "No application with less than 12 months time-in-business is sent to the model."
- "No transaction from a sanctioned entity is ever passed on for scoring."
- "This class of claims is always routed to a human."
Model contract
- "Given valid, normalized inputs, the model must rank higher-risk cases above lower-risk cases 95% of the time on this test set."
- "The model must not override deterministic rules; it only scores within the allowed space."
- "The model must stay within this calibrated probability range for these segments."
Human contract
- "Underwriters must document overrides and choose a reason code from this list."
- "Analysts must review all alerts above a certain severity within N hours."
- "Operators can only bypass the system via this explicit pathway."
These contracts don't need to be perfect on day one. They do need to exist.
Without local contracts, every incident turns into opinion.
Step 3: Attach metrics to each part
Now you can attach local metrics that tell you, in production, whether each actor is doing its job.
Rules metrics
- Coverage: What percentage of traffic actually passes through critical rules?
- Consistency: Are the same rules firing in all channels (web, API, partner)?
- Violations: How often do we detect cases that should have been caught by rules but weren't?
Model metrics
- Discriminative power: AUC / precision-recall / ranking metrics on fresh data.
- Calibration: Do scores match actual outcomes over time?
- Drift: How quickly does performance degrade by segment?
Human metrics
- Override rate: How often do humans reject or adjust model suggestions?
- Override direction: Are they systematically more conservative or more aggressive than the model?
- Latency and backlog: Are humans actually able to keep up with the cases the system routes to them?
The Composite Accountability Matrix
| Actor | Role (Goal) | Contract (Success) | Metric (Evidence) |
|---|---|---|---|
| Rules | Invariant enforcement | Catch all policy violations | % Violation catch-rate, coverage |
| Models | Probabilistic scoring | Correct ranking/calibration | AUC, Precision/Recall, Drift |
| Humans | Judgment & Edge cases | Documented, justified overrides | Override rate, reason code accuracy |
| Orchestrator | Routing & Coordination | Correct path selection | Routing accuracy, SLA compliance |
When something goes wrong, you don't just see "default rate went up." You see where the anomaly started.
Step 4: Instrument the flow for blame (in the good sense)
Composite accountability requires data about the decision path, not just the outcome.
For every major decision, log: - Which rules fired (and on which inputs) - Which model(s) were called, with inputs and outputs - Which human touched the case, what they saw, and what they chose - The final action and its timestamp - The link from that action to the eventual outcome (e.g., repayment, fraud confirmed, claim reversed)
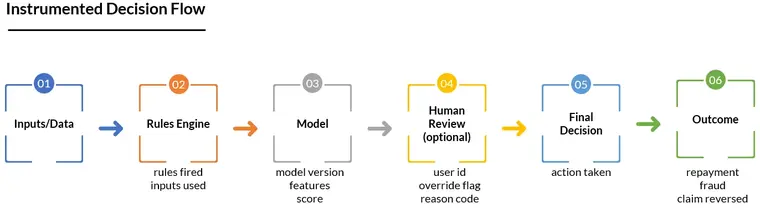
Later, when something fails, you can ask: - Did the rules allow something they shouldn't have? - Did the model assign an obviously wrong score? - Did the human override a sensible recommendation? - Or did the orchestration route the case to the wrong path entirely?
Blame here isn't about punishment. It's about locating the defect so you can fix the right thing.
Step 5: Run "component-level" postmortems
Traditional postmortems focus on the system as a whole. In a composite setup, you want to ask:
Was the data valid? If not, this is a data / ingestion / validation problem. Fix: better checks before rules and models ever run.
Did the rules behave per contract? If a clear rule should have caught the issue and didn't, update or tighten the rule layer. If no rule existed, decide whether this should become a new invariant.
Did the model behave per contract? If the inputs were valid and rules were respected, but the model still made a bad call, this is a modelling / evaluation issue.
Did the human follow their contract? If the system surfaced the right signals but the human ignored them, this is training, incentives, or policy.
Did the orchestration make sense? Sometimes all components behaved as specified, but the routing logic was flawed (e.g., what was auto-approved vs. escalated).
The goal is to end a postmortem with a sentence like: "This incident was caused by a missing rule in the front-door layer, not by the model." or "The model did what it was told; the contract was wrong for this segment."
That's composite accountability in action.

Why this matters for governance (and trust)
Composite accountability builds trust by providing clear, auditable evidence for every AI decision, eliminating the "black box" excuse and ensuring regulatory compliance.
When regulators, customers, or internal leadership ask, "Why did the system do this?", saying "the AI screwed up" is no longer acceptable.
With composite accountability you can say: - "Here are the exact rules that applied." - "Here is the model's input and output at the time." - "Here is who overrode what, and why." - "Here is the metric that told us this part of the system was off, and what we changed."
You move from superstition to structured responsibility: - Product and engineering own orchestration and contracts - Data/ML own model behavior against agreed metrics - Risk, compliance, and operations own rules and human procedures
And nobody gets to shrug and say "the AI did it" ever again.
A simple checklist to get started
For any AI-heavy system you own, ask: - Can I clearly state what rules, models, and humans are each responsible for? - Do I have at least one local metric for each part? - Do I log enough about each decision to reconstruct which parts were involved? - When something goes wrong, can I point to a specific contract that was violated—or admit that no contract existed? - Is there a process to update contracts, metrics, and routing when we learn from incidents?
If the answer to most of these is "no," your system might be intelligent, but it isn't accountable yet.
Composite intelligence was about how rules, models, and humans work together. Composite accountability is about how you prove each one did its job.
Without both, you don't really have an AI system. You have a very complicated way to say, "We're not quite sure why that happened."
Related in this series
- How to build AI Audit Trails: Learn how to capture the evidence needed for accountability.
- What are the 4 levels of AI autonomy?: See how Control Tiers define the scope of accountability.
Download the Architecture of Proof Checklist
Ready to implement? Get the definitive checklist for building verifiable AI systems.