The AI Model Review Playbook: A Step-by-Step Process for Production Models | AI Governance
This post is part of the Governance Operating Model pillar.
Most organizations monitor their models. Fewer review them.
The difference is consequential. Monitoring tells you whether current metrics are within acceptable ranges. A review asks whether the model's original assumptions still hold, whether its scope has drifted, whether its contracts are still the right contracts, and whether the evidence supports continued operation at the current autonomy tier.
This playbook defines the process for a structured model review from trigger to output.
When to run a model review
Scheduled reviews: - High-materiality models (automated decisions with significant financial, legal, or customer impact): quarterly - Medium-materiality models: semi-annual - Low-materiality models: annual - All models: after any major retraining
Triggered reviews (unscheduled): - Any drift alert that crosses the defined threshold - Any incident involving the model - Any significant change in business context (new customer segment, new product, regulatory change) - Any material change in input distributions - Any autonomy tier upgrade proposal
Who runs the review
Reviewer: A function independent of the model team — model risk, an independent data science review board, or a designated governance committee.
Participants: The model team (provides technical evidence), operations (provides outcome data), risk/compliance (confirms regulatory alignment), product (provides business context).
Accountable executive: The designated risk owner in the RACI — not the engineering manager or product lead.
The most common governance mistake in model review is letting the model team review its own model. The team that built the model has an incentive to find it acceptable and a blind spot for the assumptions they made during development.
The review evidence package
Before the review meeting, the model team assembles the evidence package. This is the primary input to the review. The package must contain:
1. Performance metrics against the original contract - Current AUC, precision/recall, or domain-specific performance metrics on fresh holdout data — not training data, not the original validation set - Calibration analysis: are scores still reflecting actual probabilities? - Segment-level breakdown: is performance uniform across the segments the model is applied to, or is it stronger in some and weaker in others? - Comparison to the baseline set at deployment: has performance improved, degraded, or remained stable?
2. Population stability analysis - PSI (Population Stability Index) on key input features: has the distribution of inputs changed since the model was trained? - Any new patterns in the input population that the model was not trained on? - Volume trends: is the model being called for a significantly different volume or mix of cases than at deployment?
3. Outcome linkage - For models where outcome data is available (credit default, fraud confirmation, claims paid): what do actual outcomes look like for decisions made by this model? - If the model is a ranking or scoring model, does the ordering of scores correlate with observed outcomes?
4. Scope compliance - Is the model being applied to cases within its defined scope? - Any evidence of scope creep — the model being used for decision types it was not validated for?
5. Contract compliance - Is the model meeting all the thresholds defined in its performance contract? - Were any circuit breakers triggered since the last review? If so, what caused them and how were they resolved?
6. Incident summary - Any incidents attributable to the model since the last review, their root causes, and the remediation actions taken
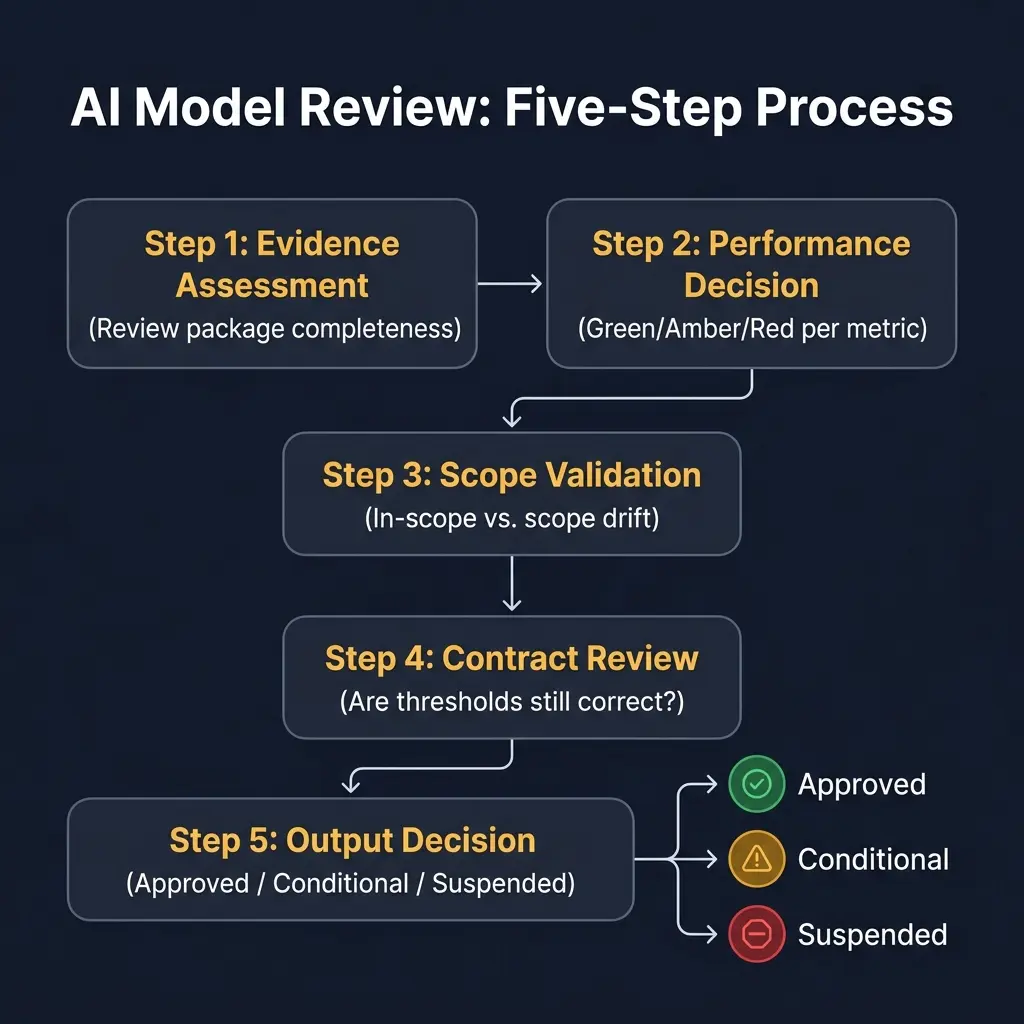
The five-step review process
Step 1: Evidence assessment (30 minutes)
Reviewers read the evidence package before the meeting. The meeting begins with any clarifying questions on the evidence — not with a summary of the evidence by the model team.
The first question: is the evidence package complete? If required data is missing — particularly fresh holdout performance or outcome linkage — the review cannot proceed until it is provided.
Step 2: Performance decision (20 minutes)
The reviewers assess each metric against its contract threshold.
For each metric: - Green: Meets or exceeds the contract threshold - Amber: Below threshold but within a defined acceptable tolerance; must be documented and monitored - Red: Breaches the contract threshold; requires a remediation decision
Any Red metric requires the review to address it explicitly in the output. It cannot be noted and deferred.
Step 3: Scope validation (15 minutes)
The reviewers assess whether the model is being used for the cases it was designed for.
Questions: - Have any new customer segments, products, or channels been added to the scope since the last review? - Has the input distribution shifted enough that the model's training population is no longer representative? - Is the model being used for decisions that were not explicitly included in its original validation?
Scope drift is the most common unreviewed risk in production models. A model validated for prime credit applicants being applied to thin-file applicants is not a model configuration error — it is a scope failure.
Step 4: Contract review (15 minutes)
The reviewers ask whether the existing contract thresholds are still the right thresholds.
This is the step most reviews skip. The original contract was written based on the business context and risk appetite at deployment. Both may have changed.
Questions: - Have regulatory requirements changed in a way that affects the performance bar? - Has the business risk appetite changed in a way that should raise or lower the acceptable error rate? - Have the decisions made by this model increased or decreased in materiality since the original contract was set?
If the thresholds need to change, that is a contract update — which requires the same sign-off process as the original contract.
Step 5: Output decision (10 minutes)
The review produces one of three mandatory outputs. No other outputs are acceptable.
✅ Approved: The model meets its performance contract, is applied within its defined scope, and is authorized to continue operating at its current autonomy tier.
⚠️ Conditional approval: The model has one or more Amber or Red findings, but continued operation is acceptable under defined conditions: specific remediation actions, a defined timeline, and a follow-up review date. Conditional approvals expire at the follow-up date — if remediation is not complete, the model defaults to suspension.
🛑 Suspended pending remediation: The model's performance or scope findings are severe enough that continued operation at the current tier is not authorized. The model must move to a lower tier or be taken offline until remediation is complete.
The output is documented in the governance log, communicated to all RACI stakeholders, and filed in the model inventory.
What a review is not
A review is not a dashboard check. Looking at monitoring dashboards and confirming metrics are green is monitoring. It is not a review. A review asks whether the metrics themselves are still the right metrics.
A review is not a retraining trigger conversation. Whether to retrain the model is a separate decision. The review determines whether the model can continue operating. Retraining is one possible remediation.
A review is not optional when metrics look fine. Metrics looking fine in aggregate is consistent with significant problems at the segment level. Scheduled reviews run on schedule.
The output documentation
Every review produces a one-page summary:
| Field | Content |
|---|---|
| Review date | |
| Model name and version | |
| Reviewer(s) | |
| Evidence package status | Complete / Incomplete (specify) |
| Performance findings | Green / Amber / Red per metric |
| Scope findings | In scope / Scope drift detected (specify) |
| Contract changes | None / Updated (specify) |
| Output decision | Approved / Conditional / Suspended |
| Conditions (if applicable) | Remediation actions, timeline, follow-up date |
| Next scheduled review | |
| Approving executive |
This document is filed in the model inventory. It is the evidence that governance is functioning — not just monitoring.
Related in this pillar
- Governance Operating Model: The full framework for AI governance operations.
- AI Governance RACI: Who owns model review and how ownership is structured.
- How to Write AI Component Contracts: The contracts that model reviews evaluate.
Download the Architecture of Proof Checklist
Ready to implement? Get the definitive checklist for building verifiable AI systems.