The First 5 Minutes: Why Your AI Product Is Already Leaking Value

One of the most dangerous myths in AI product management is that infrastructure costs are purely an "engineering problem." They aren't. In the age of token-based pricing and agentic loops, cost is a fundamental product constraint.
If your feature is "live" and user engagement looks good, but infrastructure costs are growing at 1.5x the rate of revenue, you have fallen into the 5-Minute Trap.
The Economic Symptom: "Inference Slop"
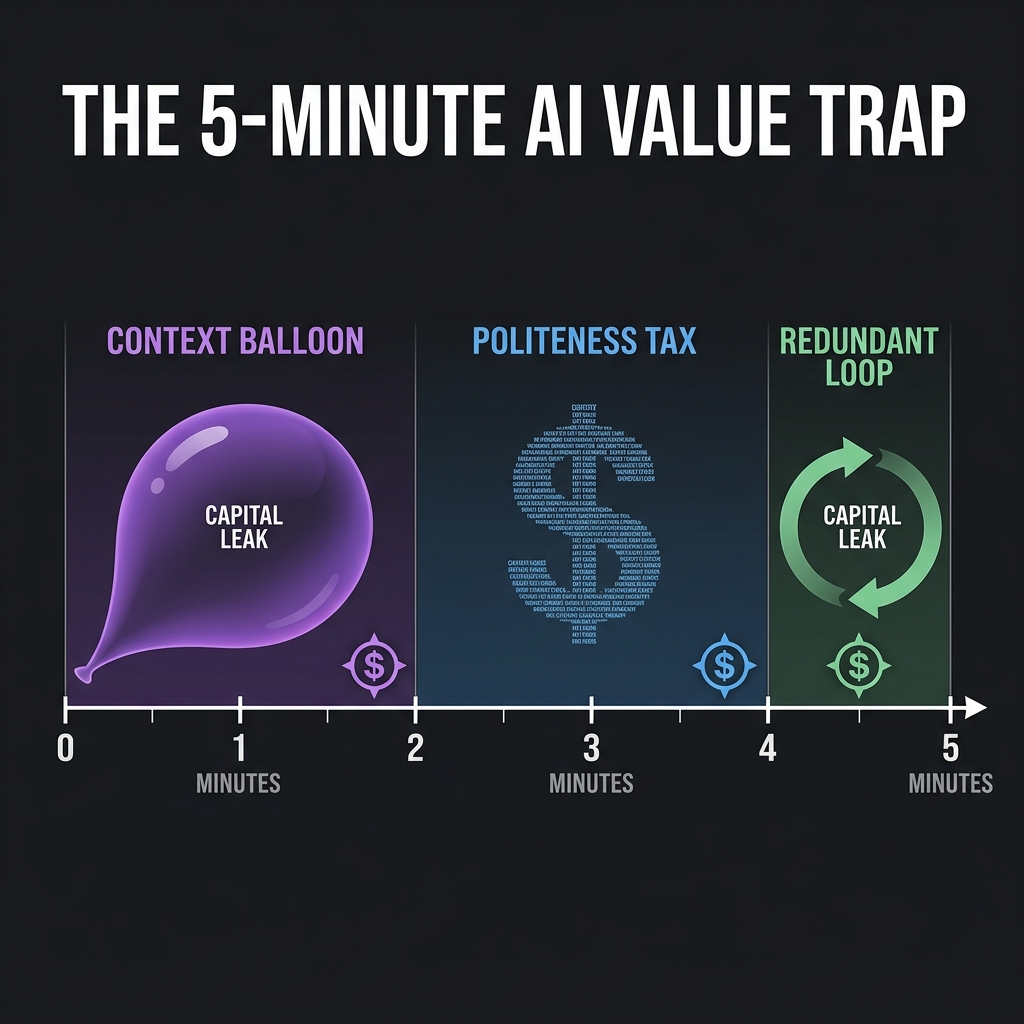
We’ve all seen the dashboards: the feature is "live," user engagement looks good, but the infrastructure costs are growing at 1.5x the rate of revenue. This is the 5-minute trap, manifesting in three distinct stages:
1) Minute 0–2: The "Context Balloon"
- The Problem: Every time a session starts, your system feels the need to "introduce" the AI to the user’s history or system instructions.
- The Leak: If you are using a standard agentic pattern, the system often sends the entire chat history plus ~300–500 tokens of System Instructions (branding, tone, safety guardrails) with every single turn.
- The Math: A 500-token system prompt across a 10-turn session can add up to ~5,000 tokens. Not all of this is wasted, but the marginal value quickly approaches zero. You’re paying for context the user doesn't experience.
2) Minute 2–4: The "Politeness Tax"
- The Problem: LLMs are trained to be helpful, safe, and agreeable. This manifests as "slop": "Certainly! I’d be happy to help you with that. Here is the information you requested..."
- The Leak: That is ~20–50 tokens of low-signal text per response.
- At Scale: In a system with 100K daily sessions, this becomes millions of tokens per day spent on tone, not outcomes. If you are using a premium model, that's thousands of dollars per day spent on being polite, not on solving the problem. You’re paying for language the user often ignores.
3) Minute 5: The "Redundant Processing Loop"
- The Problem: Modern AI agents often loop. They plan, reflect, and re-read their own prior outputs to ensure "accuracy."
- The Leak: By minute 5, the model is often re-processing its own Minute 1 and Minute 3 outputs to "verify" consistency.
- The Math: For complex workflows, this is useful. For simple tasks, it’s often over-applied. You are paying the model to read itself. It's the AI equivalent of a meeting that could have been an email.
This Is Not an Engineering Problem
It’s easy to treat this as an optimization issue involving caching, batching, or parallelization. Those help—but they don’t fix the core issue. You designed a system that trades company capital for user convenience without pricing that trade-off into the experience. That is a product decision.
graph LR
A[User Query] --> B{Value Gate}
B -- Low Value --> C[Cheap Path / Cache]
B -- High Value --> D[Expensive Path / Logic]
C --> E[Response]
D --> E
style B fill:#f3e5f5,stroke:#7b1fa2
style C fill:#e8f5e9,stroke:#2e7d32
style D fill:#ffebee,stroke:#c62828
The Metrics That Actually Matter
Most PMs look at "Daily Active Users" or "Time Spent." Because of costs, in AI, these become vanity metrics. If you want to survive, you need to track your Contribution Margin per Interaction (CMPI):
- Revenue per Interaction (RPI): What value is actually created?
- Cost per Interaction (CPI): What is the exact price of the tokens, the cache hits, and the database lookups?
The Hidden Drivers of the Leak
Cost explosions generally come from three patterns: 1. Token Verbosity: Your model is being "polite." You’re paying for output the user already understands. 2. Context Bloat: Every request sends the entire session history back to the model. By Minute 4, you are re-processing the same data for the 10th time. 3. One-Size-Fits-All Models: Simple queries and complex workflows go through the same expensive pipeline. You are using your most expensive, smartest model to handle routine queries that a smaller, faster model could solve for 1/10th the price.
How to Diagnose Your Own Leak
Look at your logs. You’ll usually see:
| Pattern | What to look for | Impact |
|---|---|---|
| System Prompt Bloat | Prompts >300–500 tokens | High (every turn) |
| Preamble Verbosity | Repeated opening phrases | Medium (volume-driven) |
| Full History Replay | Entire chat sent each turn | Compounding cost |
Why This Is a PM Problem (Not Engineering)
Engineering can optimize execution, but the real ROI is upstream—in product decisions. As a Product Manager, your job is to:
- Define the Value Ceiling: What is the maximum cost justified for solving this user need?
- Design Under Constraints: If an interaction is too expensive, redesign the flow. Can you achieve the answer in 2 tokens instead of 200? Don’t just optimize the model; redesign the experience.
- Segment the System: Why are you sending a power user’s complex query and a casual user’s "Hi" through the same expensive compute pipeline? Simple queries should take the cheap path; complex ones take the expensive path.
The Product Fix
Focus on product constraints, not just engineering optimizations: * Prompt Compression: Strip system prompts to functional essentials. * Output Discipline: Force structured or concise responses using JSON mode, format constraints, or response length limits. * Context Windowing: Don't send everything. Send summarized history, the last few turns, and relevant state only.
The 5-Minute Challenge
Take your current product. Run a trace on a single 5-minute session from today: * How many tokens were fired? * What was the exact cost of that session? * What percentage of the output actually created value?
That last number is the uncomfortable one. If it scares you, stop building new features. Start building the metrics that expose the leak.
The Real Shift
This isn’t about making models faster. It’s about asking: “What is the minimum computation required to deliver user value?”
That’s a product question. Engineering helps you execute it. But the decision to remove unnecessary work is upstream.
The Bottom Line
Most AI products don't fail because models are bad. They fail because they do too much work for too little incremental value at too high a cost.
Stop optimizing the model. Start redesigning the experience.
Download the Architecture of Proof Checklist
Ready to implement? Get the definitive checklist for building verifiable AI systems.